在 Vision Transformers 中学习 Tokenization
作者: Aritra Roy Gosthipaty, Sayak Paul (同等贡献),转换为 Keras 3 者:Muhammad Anas Raza
创建日期 2021/12/10
最后修改 2023/08/14
描述: 为 Vision Transformers 自适应地生成更少数量的 token。

引言
Vision Transformers (Dosovitskiy 等) 和许多其他基于 Transformer 的架构 (Liu 等, Yuan 等, 等) 在图像识别方面取得了显著成果。以下简要概述了用于图像分类的 Vision Transformer 架构中涉及的组件
- 从输入图像中提取小的 patch。
- 对这些 patch 进行线性投影。
- 向这些线性投影添加位置嵌入。
- 将这些投影通过一系列 Transformer (Vaswani 等) 块。
- 最后,获取最终 Transformer 块的表示,并添加一个分类头部。
如果我们使用 224x224 的图像并提取 16x16 的 patch,每张图像总共有 196 个 patch(也称为 token)。patch 的数量随着分辨率的提高而增加,导致更高的内存占用。我们是否可以在不牺牲性能的情况下使用减少数量的 patch?Ryoo 等人在 TokenLearner: Adaptive Space-Time Tokenization for Videos 中研究了这个问题。他们引入了一种称为 TokenLearner 的新型模块,可以帮助 Vision Transformer (ViT) 自适应地减少使用的 patch 数量。通过将 TokenLearner 集成到标准 ViT 架构中,他们能够减少模型使用的计算量(以 FLOPS 衡量)。
在本示例中,我们实现了 TokenLearner 模块,并使用一个迷你 ViT 和 CIFAR-10 数据集演示了其性能。我们参考了以下资料:
导入
import keras
from keras import layers
from keras import ops
from tensorflow import data as tf_data
from datetime import datetime
import matplotlib.pyplot as plt
import numpy as np
import math
超参数
请随意更改超参数并检查您的结果。发展对架构直觉的最佳方法是进行实验。
# DATA
BATCH_SIZE = 256
AUTO = tf_data.AUTOTUNE
INPUT_SHAPE = (32, 32, 3)
NUM_CLASSES = 10
# OPTIMIZER
LEARNING_RATE = 1e-3
WEIGHT_DECAY = 1e-4
# TRAINING
EPOCHS = 1
# AUGMENTATION
IMAGE_SIZE = 48 # We will resize input images to this size.
PATCH_SIZE = 6 # Size of the patches to be extracted from the input images.
NUM_PATCHES = (IMAGE_SIZE // PATCH_SIZE) ** 2
# ViT ARCHITECTURE
LAYER_NORM_EPS = 1e-6
PROJECTION_DIM = 128
NUM_HEADS = 4
NUM_LAYERS = 4
MLP_UNITS = [
PROJECTION_DIM * 2,
PROJECTION_DIM,
]
# TOKENLEARNER
NUM_TOKENS = 4
加载并准备 CIFAR-10 数据集
# Load the CIFAR-10 dataset.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
(x_train, y_train), (x_val, y_val) = (
(x_train[:40000], y_train[:40000]),
(x_train[40000:], y_train[40000:]),
)
print(f"Training samples: {len(x_train)}")
print(f"Validation samples: {len(x_val)}")
print(f"Testing samples: {len(x_test)}")
# Convert to tf.data.Dataset objects.
train_ds = tf_data.Dataset.from_tensor_slices((x_train, y_train))
train_ds = train_ds.shuffle(BATCH_SIZE * 100).batch(BATCH_SIZE).prefetch(AUTO)
val_ds = tf_data.Dataset.from_tensor_slices((x_val, y_val))
val_ds = val_ds.batch(BATCH_SIZE).prefetch(AUTO)
test_ds = tf_data.Dataset.from_tensor_slices((x_test, y_test))
test_ds = test_ds.batch(BATCH_SIZE).prefetch(AUTO)
Training samples: 40000
Validation samples: 10000
Testing samples: 10000
数据增强
增强流水线包括
- 缩放
- 调整大小
- 随机裁剪(固定大小或随机大小)
- 随机水平翻转
data_augmentation = keras.Sequential(
[
layers.Rescaling(1 / 255.0),
layers.Resizing(INPUT_SHAPE[0] + 20, INPUT_SHAPE[0] + 20),
layers.RandomCrop(IMAGE_SIZE, IMAGE_SIZE),
layers.RandomFlip("horizontal"),
],
name="data_augmentation",
)
请注意,图像数据增强层在推理时不应用数据转换。这意味着当使用 training=False 调用这些层时,它们的行为有所不同。有关更多详细信息,请参阅文档。
位置嵌入模块
一个 Transformer 架构主要由多头自注意力层和全连接前馈网络(MLP)组成。这两个组件都是置换不变的:它们不知道特征的顺序。
为了克服这个问题,我们为 token 注入位置信息。position_embedding 函数将此位置信息添加到线性投影的 token 中。
class PatchEncoder(layers.Layer):
def __init__(self, num_patches, projection_dim):
super().__init__()
self.num_patches = num_patches
self.position_embedding = layers.Embedding(
input_dim=num_patches, output_dim=projection_dim
)
def call(self, patch):
positions = ops.expand_dims(
ops.arange(start=0, stop=self.num_patches, step=1), axis=0
)
encoded = patch + self.position_embedding(positions)
return encoded
def get_config(self):
config = super().get_config()
config.update({"num_patches": self.num_patches})
return config
Transformer 的 MLP 块
这作为我们 Transformer 的全连接前馈块。
def mlp(x, dropout_rate, hidden_units):
# Iterate over the hidden units and
# add Dense => Dropout.
for units in hidden_units:
x = layers.Dense(units, activation=ops.gelu)(x)
x = layers.Dropout(dropout_rate)(x)
return x
TokenLearner 模块
下图是该模块的图解概述(来源)。
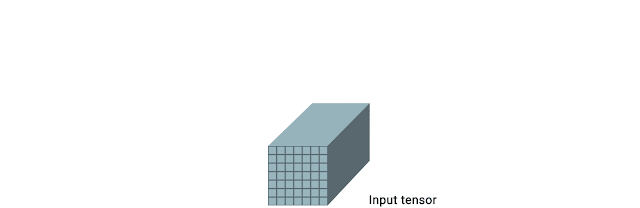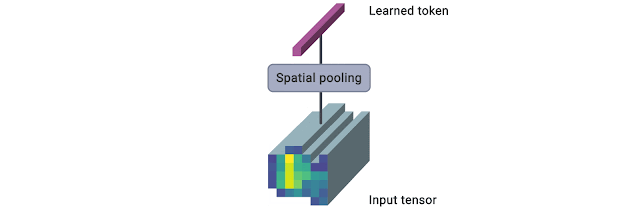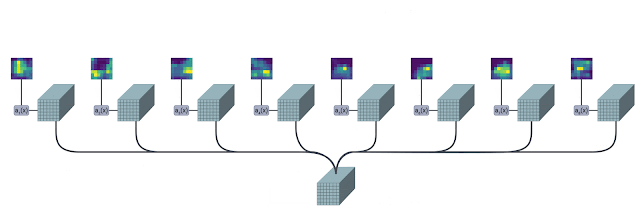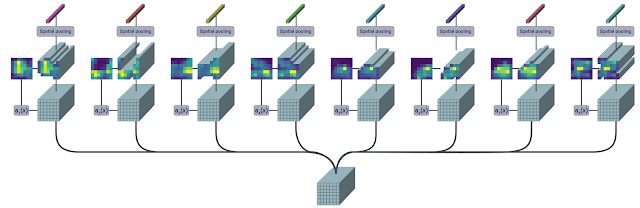
TokenLearner 模块接收图像形状的张量作为输入。然后,它将其通过多个单通道卷积层,提取不同的空间注意力图,专注于输入的各个部分。这些注意力图随后与输入进行逐元素乘法,结果通过池化进行聚合。这个池化输出可以被视为输入的摘要,其 patch 数量(例如 8 个)比原始的(例如 196 个)少得多。
使用多个卷积层有助于提高表达能力。施加某种形式的空间注意力有助于保留输入中的相关信息。这两个组件对于使 TokenLearner 工作至关重要,尤其是在我们大幅减少 patch 数量时。
def token_learner(inputs, number_of_tokens=NUM_TOKENS):
# Layer normalize the inputs.
x = layers.LayerNormalization(epsilon=LAYER_NORM_EPS)(inputs) # (B, H, W, C)
# Applying Conv2D => Reshape => Permute
# The reshape and permute is done to help with the next steps of
# multiplication and Global Average Pooling.
attention_maps = keras.Sequential(
[
# 3 layers of conv with gelu activation as suggested
# in the paper.
layers.Conv2D(
filters=number_of_tokens,
kernel_size=(3, 3),
activation=ops.gelu,
padding="same",
use_bias=False,
),
layers.Conv2D(
filters=number_of_tokens,
kernel_size=(3, 3),
activation=ops.gelu,
padding="same",
use_bias=False,
),
layers.Conv2D(
filters=number_of_tokens,
kernel_size=(3, 3),
activation=ops.gelu,
padding="same",
use_bias=False,
),
# This conv layer will generate the attention maps
layers.Conv2D(
filters=number_of_tokens,
kernel_size=(3, 3),
activation="sigmoid", # Note sigmoid for [0, 1] output
padding="same",
use_bias=False,
),
# Reshape and Permute
layers.Reshape((-1, number_of_tokens)), # (B, H*W, num_of_tokens)
layers.Permute((2, 1)),
]
)(
x
) # (B, num_of_tokens, H*W)
# Reshape the input to align it with the output of the conv block.
num_filters = inputs.shape[-1]
inputs = layers.Reshape((1, -1, num_filters))(inputs) # inputs == (B, 1, H*W, C)
# Element-Wise multiplication of the attention maps and the inputs
attended_inputs = (
ops.expand_dims(attention_maps, axis=-1) * inputs
) # (B, num_tokens, H*W, C)
# Global average pooling the element wise multiplication result.
outputs = ops.mean(attended_inputs, axis=2) # (B, num_tokens, C)
return outputs
Transformer 块
def transformer(encoded_patches):
# Layer normalization 1.
x1 = layers.LayerNormalization(epsilon=LAYER_NORM_EPS)(encoded_patches)
# Multi Head Self Attention layer 1.
attention_output = layers.MultiHeadAttention(
num_heads=NUM_HEADS, key_dim=PROJECTION_DIM, dropout=0.1
)(x1, x1)
# Skip connection 1.
x2 = layers.Add()([attention_output, encoded_patches])
# Layer normalization 2.
x3 = layers.LayerNormalization(epsilon=LAYER_NORM_EPS)(x2)
# MLP layer 1.
x4 = mlp(x3, hidden_units=MLP_UNITS, dropout_rate=0.1)
# Skip connection 2.
encoded_patches = layers.Add()([x4, x2])
return encoded_patches
带有 TokenLearner 模块的 ViT 模型
def create_vit_classifier(use_token_learner=True, token_learner_units=NUM_TOKENS):
inputs = layers.Input(shape=INPUT_SHAPE) # (B, H, W, C)
# Augment data.
augmented = data_augmentation(inputs)
# Create patches and project the pathces.
projected_patches = layers.Conv2D(
filters=PROJECTION_DIM,
kernel_size=(PATCH_SIZE, PATCH_SIZE),
strides=(PATCH_SIZE, PATCH_SIZE),
padding="VALID",
)(augmented)
_, h, w, c = projected_patches.shape
projected_patches = layers.Reshape((h * w, c))(
projected_patches
) # (B, number_patches, projection_dim)
# Add positional embeddings to the projected patches.
encoded_patches = PatchEncoder(
num_patches=NUM_PATCHES, projection_dim=PROJECTION_DIM
)(
projected_patches
) # (B, number_patches, projection_dim)
encoded_patches = layers.Dropout(0.1)(encoded_patches)
# Iterate over the number of layers and stack up blocks of
# Transformer.
for i in range(NUM_LAYERS):
# Add a Transformer block.
encoded_patches = transformer(encoded_patches)
# Add TokenLearner layer in the middle of the
# architecture. The paper suggests that anywhere
# between 1/2 or 3/4 will work well.
if use_token_learner and i == NUM_LAYERS // 2:
_, hh, c = encoded_patches.shape
h = int(math.sqrt(hh))
encoded_patches = layers.Reshape((h, h, c))(
encoded_patches
) # (B, h, h, projection_dim)
encoded_patches = token_learner(
encoded_patches, token_learner_units
) # (B, num_tokens, c)
# Layer normalization and Global average pooling.
representation = layers.LayerNormalization(epsilon=LAYER_NORM_EPS)(encoded_patches)
representation = layers.GlobalAvgPool1D()(representation)
# Classify outputs.
outputs = layers.Dense(NUM_CLASSES, activation="softmax")(representation)
# Create the Keras model.
model = keras.Model(inputs=inputs, outputs=outputs)
return model
正如 TokenLearner 论文所示,将 TokenLearner 模块包含在网络的中间几乎总是有益的。
训练工具
def run_experiment(model):
# Initialize the AdamW optimizer.
optimizer = keras.optimizers.AdamW(
learning_rate=LEARNING_RATE, weight_decay=WEIGHT_DECAY
)
# Compile the model with the optimizer, loss function
# and the metrics.
model.compile(
optimizer=optimizer,
loss="sparse_categorical_crossentropy",
metrics=[
keras.metrics.SparseCategoricalAccuracy(name="accuracy"),
keras.metrics.SparseTopKCategoricalAccuracy(5, name="top-5-accuracy"),
],
)
# Define callbacks
checkpoint_filepath = "/tmp/checkpoint.weights.h5"
checkpoint_callback = keras.callbacks.ModelCheckpoint(
checkpoint_filepath,
monitor="val_accuracy",
save_best_only=True,
save_weights_only=True,
)
# Train the model.
_ = model.fit(
train_ds,
epochs=EPOCHS,
validation_data=val_ds,
callbacks=[checkpoint_callback],
)
model.load_weights(checkpoint_filepath)
_, accuracy, top_5_accuracy = model.evaluate(test_ds)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
print(f"Test top 5 accuracy: {round(top_5_accuracy * 100, 2)}%")
使用 TokenLearner 训练和评估 ViT
vit_token_learner = create_vit_classifier()
run_experiment(vit_token_learner)
157/157 ━━━━━━━━━━━━━━━━━━━━ 303s 2s/step - accuracy: 0.1158 - loss: 2.4798 - top-5-accuracy: 0.5352 - val_accuracy: 0.2206 - val_loss: 2.0292 - val_top-5-accuracy: 0.7688
40/40 ━━━━━━━━━━━━━━━━━━━━ 5s 133ms/step - accuracy: 0.2298 - loss: 2.0179 - top-5-accuracy: 0.7723
Test accuracy: 22.9%
Test top 5 accuracy: 77.22%
结果
我们测试了在我们实现的迷你 ViT 中是否包含 TokenLearner(使用本示例中给出的相同超参数)。以下是我们的结果:
| TokenLearner | 输入 Token 数 TokenLearner |
Top-1 Acc (5 次运行平均) |
GFLOPs | TensorBoard |
|---|---|---|---|---|
| N | - | 56.112% | 0.0184 | 链接 |
| Y | 8 | 56.55% | 0.0153 | 链接 |
| N | - | 56.37% | 0.0184 | 链接 |
| Y | 4 | 56.4980% | 0.0147 | 链接 |
| N | - (Transformer 层数:8) | 55.36% | 0.0359 | 链接 |
TokenLearner 能够始终优于没有该模块的迷你 ViT。有趣的是,它也能优于更深的迷你 ViT 版本(具有 8 层)。作者在论文中也报告了类似的观察结果,并将其归因于 TokenLearner 的自适应性。
还应注意,添加 TokenLearner 模块后,FLOPS 计算量显著减少。在 FLOPS 计算量较少的情况下,TokenLearner 模块能够提供更好的结果。这与作者的发现非常吻合。
此外,作者引入了一个适用于较小训练数据规模的更新版 TokenLearner。引用作者的话:
这个版本没有使用 4 个小通道的卷积层来实现空间注意力,而是使用 2 个分组卷积层,通道数更多。它还使用 softmax 代替 sigmoid。我们证实此版本在训练数据有限(例如从头开始使用 ImageNet1K 训练)时效果更好。
我们测试了这个模块,下表总结了结果:
| 分组数 | Token 数 | Top-1 Acc | GFLOPs | TensorBoard |
|---|---|---|---|---|
| 4 | 4 | 54.638% | 0.0149 | 链接 |
| 8 | 8 | 54.898% | 0.0146 | 链接 |
| 4 | 8 | 55.196% | 0.0149 | 链接 |
请注意,我们使用了本示例中提供的相同超参数。我们的实现可在此 notebook 中获取。我们承认,使用此新 TokenLearner 模块的结果略低于预期,这可以通过超参数调优来缓解。
注意:为了计算我们模型的 FLOPs,我们使用了此工具,来自此仓库。
参数数量
您可能已经注意到,添加 TokenLearner 模块会增加基础网络的参数数量。但这并不意味着它效率较低,正如 Dehghani 等人所示。 Bello 等人也报告了类似的发现。 TokenLearner 模块有助于减少整个网络的 FLOPS,从而有助于减少内存占用。
最后说明
- TokenFuser:论文作者还提出了另一个名为 TokenFuser 的模块。该模块有助于将 TokenLearner 输出的表示重新映射回其原始空间分辨率。要在 ViT 架构中重复使用 TokenLearner,TokenFuser 是必需的。我们首先从 TokenLearner 中学习 token,从 Transformer 层构建 token 的表示,然后将该表示重新映射回原始空间分辨率,以便它可以再次被 TokenLearner 消耗。请注意,如果 TokenLearner 模块未与 TokenFuser 配对,则在整个 ViT 模型中只能使用一次 TokenLearner 模块。
- 将这些模块用于视频:作者还建议 TokenFuser 与 Vision Transformers for Videos (Arnab 等) 非常契合。
我们感谢 JarvisLabs 和 Google Developers Experts 项目提供的 GPU 积分。此外,我们感谢 Michael Ryoo(TokenLearner 的第一作者)富有成效的讨论。