增强深度残差网络用于单图像超分辨率
作者: Gitesh Chawda
创建日期 2022/04/07
最后修改日期 2024/08/27
描述: 在 DIV2K 数据集上训练 EDSR 模型。

简介
在本示例中,我们实现 Bee Lim、Sanghyun Son、Heewon Kim、Seungjun Nah 和 Kyoung Mu Lee 的论文《增强深度残差网络用于单图像超分辨率 (EDSR)》。
EDSR 架构基于 SRResNet 架构,由多个残差块组成。它使用恒定的缩放层代替批归一化层以产生一致的结果(输入和输出具有相似的分布,因此归一化中间特征可能并非理想)。作者没有使用 L2 损失(均方误差),而是采用了 L1 损失(平均绝对误差),这在经验上表现更好。
我们的实现只包含 16 个残差块,通道数为 64。
或者,如 Keras 示例《使用高效子像素 CNN 进行图像超分辨率》所示,您可以使用 ESPCN 模型进行超分辨率。根据综述论文,EDSR 是基于 PSNR 分数表现最好的五种超分辨率方法之一。然而,它比其他方法拥有更多参数,需要更多的计算能力。它的 PSNR 值 (≈34db) 略高于 ESPCN (≈32db)。根据综述论文,EDSR 的性能优于 ESPCN。
比较图: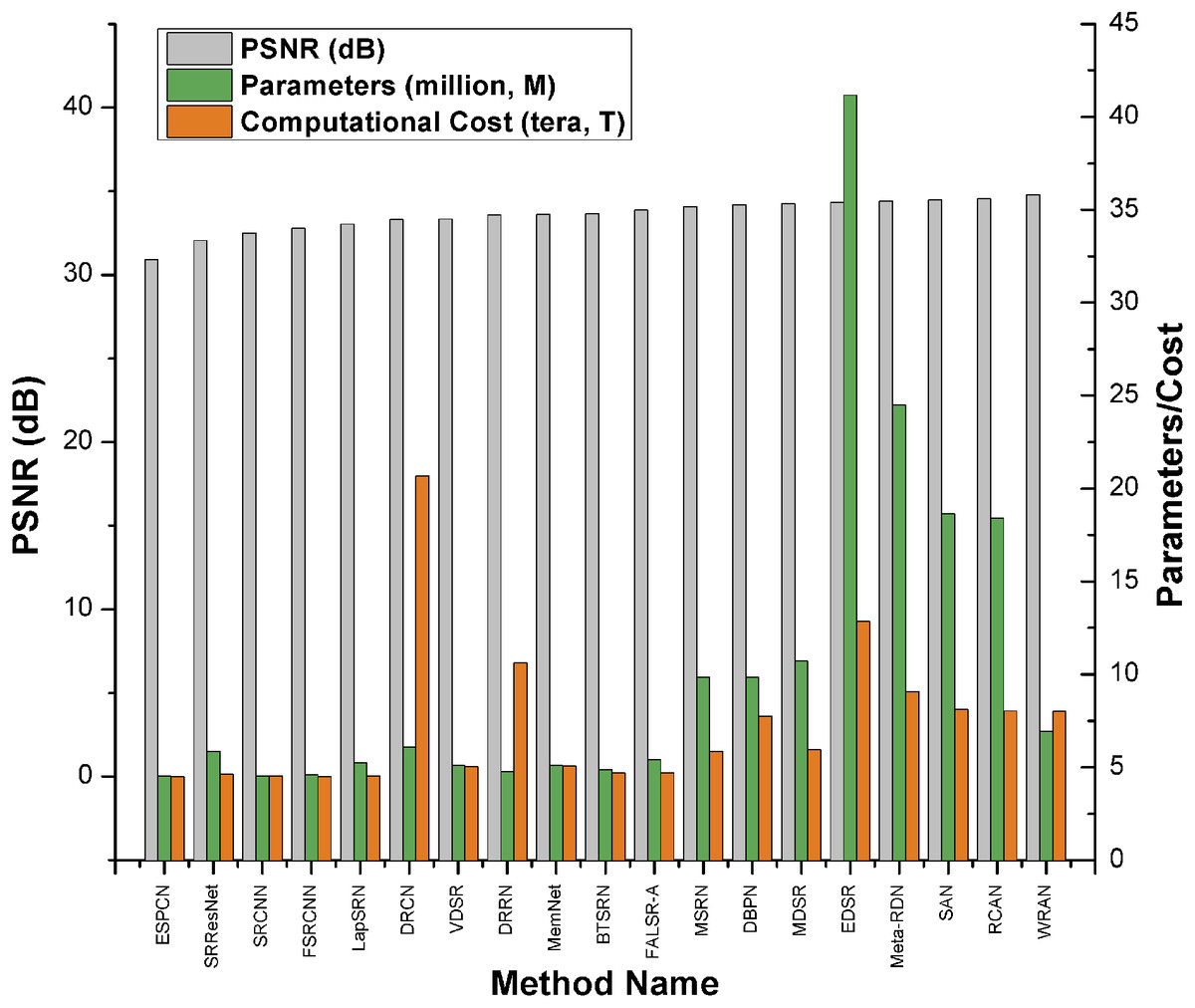
导入
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
import keras
from keras import layers
from keras import ops
AUTOTUNE = tf.data.AUTOTUNE
下载训练数据集
我们使用 DIV2K 数据集,这是一个著名的单图像超分辨率数据集,包含 1,000 张具有各种降级场景的图像,分为 800 张训练图像、100 张验证图像和 100 张测试图像。我们使用 4 倍双三次下采样图像作为“低质量”参考。
# Download DIV2K from TF Datasets
# Using bicubic 4x degradation type
div2k_data = tfds.image.Div2k(config="bicubic_x4")
div2k_data.download_and_prepare()
# Taking train data from div2k_data object
train = div2k_data.as_dataset(split="train", as_supervised=True)
train_cache = train.cache()
# Validation data
val = div2k_data.as_dataset(split="validation", as_supervised=True)
val_cache = val.cache()
翻转、裁剪和调整图像大小
def flip_left_right(lowres_img, highres_img):
"""Flips Images to left and right."""
# Outputs random values from a uniform distribution in between 0 to 1
rn = keras.random.uniform(shape=(), maxval=1)
# If rn is less than 0.5 it returns original lowres_img and highres_img
# If rn is greater than 0.5 it returns flipped image
return ops.cond(
rn < 0.5,
lambda: (lowres_img, highres_img),
lambda: (
ops.flip(lowres_img),
ops.flip(highres_img),
),
)
def random_rotate(lowres_img, highres_img):
"""Rotates Images by 90 degrees."""
# Outputs random values from uniform distribution in between 0 to 4
rn = ops.cast(
keras.random.uniform(shape=(), maxval=4, dtype="float32"), dtype="int32"
)
# Here rn signifies number of times the image(s) are rotated by 90 degrees
return tf.image.rot90(lowres_img, rn), tf.image.rot90(highres_img, rn)
def random_crop(lowres_img, highres_img, hr_crop_size=96, scale=4):
"""Crop images.
low resolution images: 24x24
high resolution images: 96x96
"""
lowres_crop_size = hr_crop_size // scale # 96//4=24
lowres_img_shape = ops.shape(lowres_img)[:2] # (height,width)
lowres_width = ops.cast(
keras.random.uniform(
shape=(), maxval=lowres_img_shape[1] - lowres_crop_size + 1, dtype="float32"
),
dtype="int32",
)
lowres_height = ops.cast(
keras.random.uniform(
shape=(), maxval=lowres_img_shape[0] - lowres_crop_size + 1, dtype="float32"
),
dtype="int32",
)
highres_width = lowres_width * scale
highres_height = lowres_height * scale
lowres_img_cropped = lowres_img[
lowres_height : lowres_height + lowres_crop_size,
lowres_width : lowres_width + lowres_crop_size,
] # 24x24
highres_img_cropped = highres_img[
highres_height : highres_height + hr_crop_size,
highres_width : highres_width + hr_crop_size,
] # 96x96
return lowres_img_cropped, highres_img_cropped
准备一个 tf.data.Dataset 对象
我们通过随机水平翻转和 90 度旋转来增强训练数据。
我们使用 24x24 RGB 输入块作为低分辨率图像。
def dataset_object(dataset_cache, training=True):
ds = dataset_cache
ds = ds.map(
lambda lowres, highres: random_crop(lowres, highres, scale=4),
num_parallel_calls=AUTOTUNE,
)
if training:
ds = ds.map(random_rotate, num_parallel_calls=AUTOTUNE)
ds = ds.map(flip_left_right, num_parallel_calls=AUTOTUNE)
# Batching Data
ds = ds.batch(16)
if training:
# Repeating Data, so that cardinality if dataset becomes infinte
ds = ds.repeat()
# prefetching allows later images to be prepared while the current image is being processed
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = dataset_object(train_cache, training=True)
val_ds = dataset_object(val_cache, training=False)
可视化数据
让我们可视化一些示例图像
lowres, highres = next(iter(train_ds))
# High Resolution Images
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(highres[i].numpy().astype("uint8"))
plt.title(highres[i].shape)
plt.axis("off")
# Low Resolution Images
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(lowres[i].numpy().astype("uint8"))
plt.title(lowres[i].shape)
plt.axis("off")
def PSNR(super_resolution, high_resolution):
"""Compute the peak signal-to-noise ratio, measures quality of image."""
# Max value of pixel is 255
psnr_value = tf.image.psnr(high_resolution, super_resolution, max_val=255)[0]
return psnr_value


构建模型
在论文中,作者训练了三个模型:EDSR、MDSR 和一个基线模型。在此代码示例中,我们只训练基线模型。
与具有三个残差块的模型的比较
EDSR 的残差块设计与 ResNet 不同。批归一化层被移除(以及最终的 ReLU 激活):由于批归一化层对特征进行归一化,它们会损害输出值范围的灵活性。因此,最好将其移除。此外,这也有助于减少模型所需的 GPU RAM,因为批归一化层消耗的内存量与前面的卷积层相同。
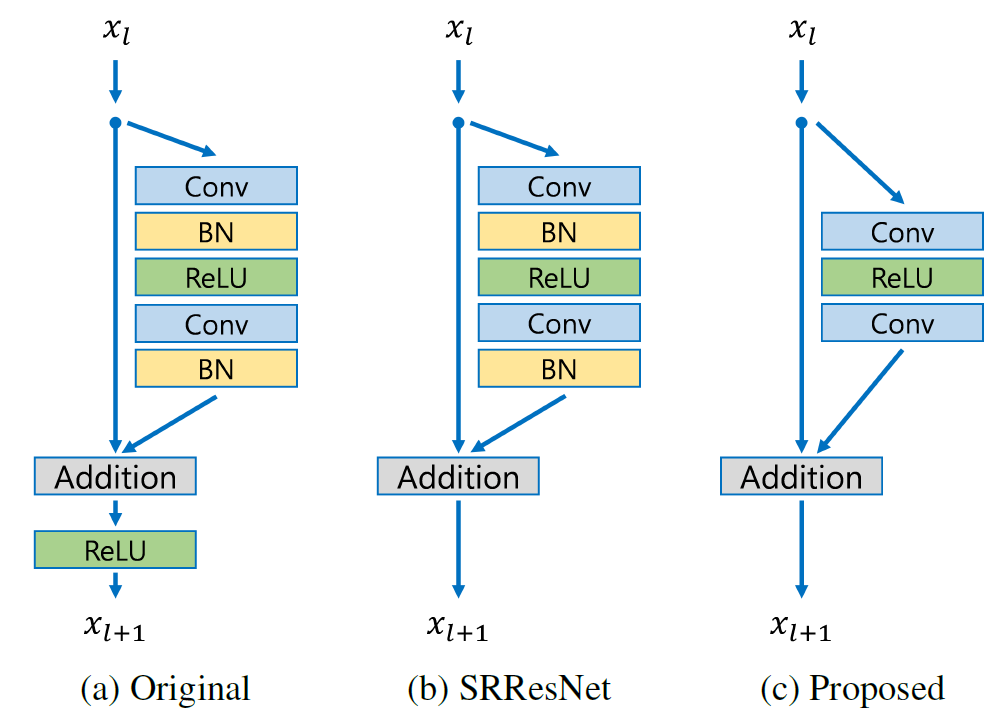
class EDSRModel(keras.Model):
def train_step(self, data):
# Unpack the data. Its structure depends on your model and
# on what you pass to `fit()`.
x, y = data
with tf.GradientTape() as tape:
y_pred = self(x, training=True) # Forward pass
# Compute the loss value
# (the loss function is configured in `compile()`)
loss = self.compiled_loss(y, y_pred, regularization_losses=self.losses)
# Compute gradients
trainable_vars = self.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Update metrics (includes the metric that tracks the loss)
self.compiled_metrics.update_state(y, y_pred)
# Return a dict mapping metric names to current value
return {m.name: m.result() for m in self.metrics}
def predict_step(self, x):
# Adding dummy dimension using tf.expand_dims and converting to float32 using tf.cast
x = ops.cast(tf.expand_dims(x, axis=0), dtype="float32")
# Passing low resolution image to model
super_resolution_img = self(x, training=False)
# Clips the tensor from min(0) to max(255)
super_resolution_img = ops.clip(super_resolution_img, 0, 255)
# Rounds the values of a tensor to the nearest integer
super_resolution_img = ops.round(super_resolution_img)
# Removes dimensions of size 1 from the shape of a tensor and converting to uint8
super_resolution_img = ops.squeeze(
ops.cast(super_resolution_img, dtype="uint8"), axis=0
)
return super_resolution_img
# Residual Block
def ResBlock(inputs):
x = layers.Conv2D(64, 3, padding="same", activation="relu")(inputs)
x = layers.Conv2D(64, 3, padding="same")(x)
x = layers.Add()([inputs, x])
return x
# Upsampling Block
def Upsampling(inputs, factor=2, **kwargs):
x = layers.Conv2D(64 * (factor**2), 3, padding="same", **kwargs)(inputs)
x = layers.Lambda(lambda x: tf.nn.depth_to_space(x, block_size=factor))(x)
x = layers.Conv2D(64 * (factor**2), 3, padding="same", **kwargs)(x)
x = layers.Lambda(lambda x: tf.nn.depth_to_space(x, block_size=factor))(x)
return x
def make_model(num_filters, num_of_residual_blocks):
# Flexible Inputs to input_layer
input_layer = layers.Input(shape=(None, None, 3))
# Scaling Pixel Values
x = layers.Rescaling(scale=1.0 / 255)(input_layer)
x = x_new = layers.Conv2D(num_filters, 3, padding="same")(x)
# 16 residual blocks
for _ in range(num_of_residual_blocks):
x_new = ResBlock(x_new)
x_new = layers.Conv2D(num_filters, 3, padding="same")(x_new)
x = layers.Add()([x, x_new])
x = Upsampling(x)
x = layers.Conv2D(3, 3, padding="same")(x)
output_layer = layers.Rescaling(scale=255)(x)
return EDSRModel(input_layer, output_layer)
model = make_model(num_filters=64, num_of_residual_blocks=16)
训练模型
# Using adam optimizer with initial learning rate as 1e-4, changing learning rate after 5000 steps to 5e-5
optim_edsr = keras.optimizers.Adam(
learning_rate=keras.optimizers.schedules.PiecewiseConstantDecay(
boundaries=[5000], values=[1e-4, 5e-5]
)
)
# Compiling model with loss as mean absolute error(L1 Loss) and metric as psnr
model.compile(optimizer=optim_edsr, loss="mae", metrics=[PSNR])
# Training for more epochs will improve results
model.fit(train_ds, epochs=100, steps_per_epoch=200, validation_data=val_ds)
Epoch 1/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 117s 472ms/step - psnr: 8.7874 - loss: 85.1546 - val_loss: 17.4624 - val_psnr: 8.7008
Epoch 10/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 58s 288ms/step - psnr: 8.9519 - loss: 94.4611 - val_loss: 8.6002 - val_psnr: 6.4303
Epoch 20/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 52s 261ms/step - psnr: 8.5120 - loss: 95.5767 - val_loss: 8.7330 - val_psnr: 6.3106
Epoch 30/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 53s 262ms/step - psnr: 8.6051 - loss: 96.1541 - val_loss: 7.5442 - val_psnr: 7.9715
Epoch 40/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 53s 263ms/step - psnr: 8.7405 - loss: 96.8159 - val_loss: 7.2734 - val_psnr: 7.6312
Epoch 50/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 52s 259ms/step - psnr: 8.7648 - loss: 95.7817 - val_loss: 8.1772 - val_psnr: 7.1330
Epoch 60/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 53s 264ms/step - psnr: 8.8651 - loss: 95.4793 - val_loss: 7.6550 - val_psnr: 7.2298
Epoch 70/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 53s 263ms/step - psnr: 8.8489 - loss: 94.5993 - val_loss: 7.4607 - val_psnr: 6.6841
Epoch 80/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 53s 263ms/step - psnr: 8.3046 - loss: 97.3796 - val_loss: 8.1050 - val_psnr: 8.0714
Epoch 90/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 53s 264ms/step - psnr: 7.9295 - loss: 96.0314 - val_loss: 7.1515 - val_psnr: 6.8712
Epoch 100/100
200/200 ━━━━━━━━━━━━━━━━━━━━ 53s 263ms/step - psnr: 8.1666 - loss: 94.9792 - val_loss: 6.6524 - val_psnr: 6.5423
<keras.src.callbacks.history.History at 0x7fc1e8dd6890>
在新图像上运行推理并绘制结果
def plot_results(lowres, preds):
"""
Displays low resolution image and super resolution image
"""
plt.figure(figsize=(24, 14))
plt.subplot(132), plt.imshow(lowres), plt.title("Low resolution")
plt.subplot(133), plt.imshow(preds), plt.title("Prediction")
plt.show()
for lowres, highres in val.take(10):
lowres = tf.image.random_crop(lowres, (150, 150, 3))
preds = model.predict_step(lowres)
plot_results(lowres, preds)




总结
在此示例中,我们实现了 EDSR 模型(增强深度残差网络用于单图像超分辨率)。您可以通过增加训练周期数以及使用具有混合降级因子的更多输入进行训练来提高模型的准确性,以便能够处理更广泛的真实世界图像。
您还可以通过实现 EDSR+、MDSR(多尺度超分辨率)和 MDSR+ 来改进给定的基线 EDSR 模型,这些都是在同一篇论文中提出的。