Segment Anything Model (SAM) 和 🤗Transformers
作者: Merve Noyan & Sayak Paul
创建日期 2023/07/11
最后修改 2023/07/11
描述: 使用 Keras 和 🤗 Transformers 微调 Segment Anything Model。

引言
大型语言模型 (LLM) 通过“提示”使用户可以轻松将其应用于各种应用程序。例如,如果我们想让一个 LLM 预测以下句子的情感——“那部电影太棒了,我非常喜欢它”——我们会使用这样的提示来提示 LLM
以下句子的情感是什么:“那部电影太棒了,我非常喜欢它”?
作为回报,LLM 将返回情感标记。
但是,当涉及到视觉识别任务时,我们如何设计“视觉”线索来提示基础视觉模型呢?例如,我们可以输入一张图像,并在图像上用边界框提示模型,要求它执行分割。这里的边界框将充当我们的视觉提示。
在Segment Anything Model(被称为 SAM)中,Meta 的研究人员将语言提示的空间扩展到了视觉提示。受大型语言模型的启发,SAM 能够通过提示输入执行零样本分割。这里的提示可以是前景/背景点集、自由文本、框或掩码。有许多下游分割任务,包括语义分割和边缘检测。SAM 的目标是通过提示实现所有这些下游分割任务。
在此示例中,我们将学习如何使用 🤗 Transformers 中的 SAM 模型进行推理和微调。
安装
!!pip install -q git+https://github.com/huggingface/transformers
[]
让我们导入此示例所需的一切。
from tensorflow import keras
from transformers import TFSamModel, SamProcessor
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.python.ops.numpy_ops import np_config
from PIL import Image
import requests
import glob
import os
/Users/mervenoyan/miniforge3/envs/py310/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
SAM 简介
SAM 包含以下组件
 |
|---|
| 图片取自官方 SAM 博客文章 |
图像编码器负责计算图像嵌入。与 SAM 交互时,我们计算一次图像嵌入(因为图像编码器很重),然后将其与上面提到的不同提示(点、边界框、掩码)重复使用。
点和框(所谓的稀疏提示)通过一个轻量级的提示编码器,而掩码(密集提示)通过一个卷积层。我们将图像编码器提取的图像嵌入和提示嵌入耦合起来,两者都进入一个轻量级的掩码解码器。解码器负责预测掩码。
 |
|---|
| 图片取自SAM 论文 |
SAM 经过预训练,可以预测任何可接受的提示的有效掩码。此要求使得 SAM 即使在提示难以理解的情况下也能输出有效掩码——这使得 SAM 具有歧义感知能力。此外,SAM 可以为单个提示预测多个掩码。
我们强烈建议您查阅SAM 论文和博客文章,以了解有关 SAM 的更多详细信息以及用于预训练它的数据集。
使用 SAM 运行推理
SAM 有三个检查点
我们在 TFSamModel 中加载 sam-vit-base。我们还需要相应检查点的 SamProcessor。
model = TFSamModel.from_pretrained("facebook/sam-vit-base")
processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
All model checkpoint layers were used when initializing TFSamModel.
All the layers of TFSamModel were initialized from the model checkpoint at facebook/sam-vit-base.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFSamModel for predictions without further training.
接下来,我们编写一些用于可视化的实用函数。这些函数大部分取自此笔记本。
np_config.enable_numpy_behavior()
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(
plt.Rectangle((x0, y0), w, h, edgecolor="green", facecolor=(0, 0, 0, 0), lw=2)
)
def show_boxes_on_image(raw_image, boxes):
plt.figure(figsize=(10, 10))
plt.imshow(raw_image)
for box in boxes:
show_box(box, plt.gca())
plt.axis("on")
plt.show()
def show_points_on_image(raw_image, input_points, input_labels=None):
plt.figure(figsize=(10, 10))
plt.imshow(raw_image)
input_points = np.array(input_points)
if input_labels is None:
labels = np.ones_like(input_points[:, 0])
else:
labels = np.array(input_labels)
show_points(input_points, labels, plt.gca())
plt.axis("on")
plt.show()
def show_points_and_boxes_on_image(raw_image, boxes, input_points, input_labels=None):
plt.figure(figsize=(10, 10))
plt.imshow(raw_image)
input_points = np.array(input_points)
if input_labels is None:
labels = np.ones_like(input_points[:, 0])
else:
labels = np.array(input_labels)
show_points(input_points, labels, plt.gca())
for box in boxes:
show_box(box, plt.gca())
plt.axis("on")
plt.show()
def show_points_and_boxes_on_image(raw_image, boxes, input_points, input_labels=None):
plt.figure(figsize=(10, 10))
plt.imshow(raw_image)
input_points = np.array(input_points)
if input_labels is None:
labels = np.ones_like(input_points[:, 0])
else:
labels = np.array(input_labels)
show_points(input_points, labels, plt.gca())
for box in boxes:
show_box(box, plt.gca())
plt.axis("on")
plt.show()
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(
pos_points[:, 0],
pos_points[:, 1],
color="green",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
ax.scatter(
neg_points[:, 0],
neg_points[:, 1],
color="red",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
def show_masks_on_image(raw_image, masks, scores):
if len(masks[0].shape) == 4:
final_masks = tf.squeeze(masks[0])
if scores.shape[0] == 1:
final_scores = tf.squeeze(scores)
nb_predictions = scores.shape[-1]
fig, axes = plt.subplots(1, nb_predictions, figsize=(15, 15))
for i, (mask, score) in enumerate(zip(final_masks, final_scores)):
mask = tf.stop_gradient(mask)
axes[i].imshow(np.array(raw_image))
show_mask(mask, axes[i])
axes[i].title.set_text(f"Mask {i+1}, Score: {score.numpy().item():.3f}")
axes[i].axis("off")
plt.show()
我们将使用点提示来分割汽车图像。调用处理器时,请确保将 return_tensors 设置为 tf。
现在让我们加载一张汽车图片并进行分割。
img_url = "https://hugging-face.cn/ybelkada/segment-anything/resolve/main/assets/car.png"
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
plt.imshow(raw_image)
plt.show()

现在让我们定义一组将用作提示的点。
input_points = [[[450, 600]]]
# Visualize a single point.
show_points_on_image(raw_image, input_points[0])

然后进行分割
# Preprocess the input image.
inputs = processor(raw_image, input_points=input_points, return_tensors="tf")
# Predict for segmentation with the prompt.
outputs = model(**inputs)
outputs 包含两个我们感兴趣的属性
outputs.pred_masks:表示预测的掩码。outputs.iou_scores:表示与掩码相关的 IoU 分数。
让我们对掩码进行后处理,并使用它们的 IoU 分数进行可视化
masks = processor.image_processor.post_process_masks(
outputs.pred_masks,
inputs["original_sizes"],
inputs["reshaped_input_sizes"],
return_tensors="tf",
)
show_masks_on_image(raw_image, masks, outputs.iou_scores)

就这样!
可以看出,所有掩码对于我们提供的点提示都是有效的掩码。
SAM 非常灵活,可以支持不同的视觉提示,我们鼓励您查阅此笔记本了解更多信息!
微调
我们将使用此数据集,其中包含乳腺癌扫描。在医学影像领域,能够分割包含恶性肿瘤的细胞是一项重要任务。
数据准备
首先获取数据集。
remote_path = "https://hugging-face.cn/datasets/sayakpaul/sample-datasets/resolve/main/breast-cancer-dataset.tar.gz"
dataset_path = keras.utils.get_file(
"breast-cancer-dataset.tar.gz", remote_path, untar=True
)
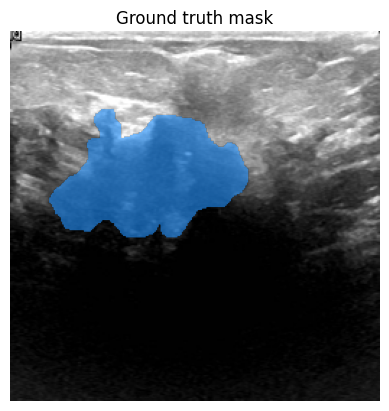
现在让我们可视化数据集中的一个样本。
(show_mask() 工具取自此笔记本)
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
# Load all the image and label paths.
image_paths = sorted(glob.glob(os.path.join(dataset_path, "images/*.png")))
label_paths = sorted(glob.glob(os.path.join(dataset_path, "labels/*.png")))
# Load the image and label.
idx = 15
image = Image.open(image_paths[idx])
label = Image.open(label_paths[idx])
image = np.array(image)
ground_truth_seg = np.array(label)
# Display.
fig, axes = plt.subplots()
axes.imshow(image)
show_mask(ground_truth_seg, axes)
axes.title.set_text(f"Ground truth mask")
axes.axis("off")
plt.show()
tf.shape(ground_truth_seg)
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([256, 256], dtype=int32)>
准备 tf.data.Dataset
现在我们编写一个生成器类,使用上面使用的 processor 准备图像和分割掩码。我们将利用此生成器类,通过使用 tf.data.Dataset.from_generator() 为我们的训练集创建一个 tf.data.Dataset 对象。此类中的实用工具已改编自此笔记本。
生成器负责生成预处理后的图像、分割掩码以及 SAM 模型所需的其他一些元数据。
class Generator:
"""Generator class for processing the images and the masks for SAM fine-tuning."""
def __init__(self, dataset_path, processor):
self.dataset_path = dataset_path
self.image_paths = sorted(
glob.glob(os.path.join(self.dataset_path, "images/*.png"))
)
self.label_paths = sorted(
glob.glob(os.path.join(self.dataset_path, "labels/*.png"))
)
self.processor = processor
def __call__(self):
for image_path, label_path in zip(self.image_paths, self.label_paths):
image = np.array(Image.open(image_path))
ground_truth_mask = np.array(Image.open(label_path))
# get bounding box prompt
prompt = self.get_bounding_box(ground_truth_mask)
# prepare image and prompt for the model
inputs = self.processor(image, input_boxes=[[prompt]], return_tensors="np")
# remove batch dimension which the processor adds by default
inputs = {k: v.squeeze(0) for k, v in inputs.items()}
# add ground truth segmentation
inputs["ground_truth_mask"] = ground_truth_mask
yield inputs
def get_bounding_box(self, ground_truth_map):
# get bounding box from mask
y_indices, x_indices = np.where(ground_truth_map > 0)
x_min, x_max = np.min(x_indices), np.max(x_indices)
y_min, y_max = np.min(y_indices), np.max(y_indices)
# add perturbation to bounding box coordinates
H, W = ground_truth_map.shape
x_min = max(0, x_min - np.random.randint(0, 20))
x_max = min(W, x_max + np.random.randint(0, 20))
y_min = max(0, y_min - np.random.randint(0, 20))
y_max = min(H, y_max + np.random.randint(0, 20))
bbox = [x_min, y_min, x_max, y_max]
return bbox
get_bounding_box() 负责将地面真实分割图转换为边界框。在微调期间,这些边界框作为提示(以及原始图像)馈送给 SAM,然后训练 SAM 预测有效掩码。
首先创建生成器,然后使用它创建 tf.data.Dataset 的优点是灵活性。有时,我们可能需要使用其他库(例如 albumentations)中的实用工具,这些工具可能没有原生的 TensorFlow 实现。通过使用此工作流程,我们可以轻松适应此类用例。
但是,非 TF 的对应实现可能会引入性能瓶颈。然而,对于我们的示例来说,它应该可以正常工作。
现在,我们从训练集准备 tf.data.Dataset。
# Define the output signature of the generator class.
output_signature = {
"pixel_values": tf.TensorSpec(shape=(3, None, None), dtype=tf.float32),
"original_sizes": tf.TensorSpec(shape=(None,), dtype=tf.int64),
"reshaped_input_sizes": tf.TensorSpec(shape=(None,), dtype=tf.int64),
"input_boxes": tf.TensorSpec(shape=(None, None), dtype=tf.float64),
"ground_truth_mask": tf.TensorSpec(shape=(None, None), dtype=tf.int32),
}
# Prepare the dataset object.
train_dataset_gen = Generator(dataset_path, processor)
train_ds = tf.data.Dataset.from_generator(
train_dataset_gen, output_signature=output_signature
)
接下来,我们配置数据集以提高性能。
auto = tf.data.AUTOTUNE
batch_size = 2
shuffle_buffer = 4
train_ds = (
train_ds.cache()
.shuffle(shuffle_buffer)
.batch(batch_size)
.prefetch(buffer_size=auto)
)
取一个数据批次,检查其中元素的形状。
sample = next(iter(train_ds))
for k in sample:
print(k, sample[k].shape, sample[k].dtype, isinstance(sample[k], tf.Tensor))
pixel_values (2, 3, 1024, 1024) <dtype: 'float32'> True
original_sizes (2, 2) <dtype: 'int64'> True
reshaped_input_sizes (2, 2) <dtype: 'int64'> True
input_boxes (2, 1, 4) <dtype: 'float64'> True
ground_truth_mask (2, 256, 256) <dtype: 'int32'> True
训练
现在我们编写 DICE loss。此实现基于MONAI DICE loss。
def dice_loss(y_true, y_pred, smooth=1e-5):
y_pred = tf.sigmoid(y_pred)
reduce_axis = list(range(2, len(y_pred.shape)))
if batch_size > 1:
# reducing spatial dimensions and batch
reduce_axis = [0] + reduce_axis
intersection = tf.reduce_sum(y_true * y_pred, axis=reduce_axis)
y_true_sq = tf.math.pow(y_true, 2)
y_pred_sq = tf.math.pow(y_pred, 2)
ground_o = tf.reduce_sum(y_true_sq, axis=reduce_axis)
pred_o = tf.reduce_sum(y_pred_sq, axis=reduce_axis)
denominator = ground_o + pred_o
# calculate DICE coefficient
loss = 1.0 - (2.0 * intersection + 1e-5) / (denominator + 1e-5)
loss = tf.reduce_mean(loss)
return loss
微调 SAM
现在我们将微调 SAM 的解码器部分。我们将冻结视觉编码器和提示编码器层。
# initialize SAM model and optimizer
sam = TFSamModel.from_pretrained("facebook/sam-vit-base")
optimizer = keras.optimizers.Adam(1e-5)
for layer in sam.layers:
if layer.name in ["vision_encoder", "prompt_encoder"]:
layer.trainable = False
@tf.function
def train_step(inputs):
with tf.GradientTape() as tape:
# pass inputs to SAM model
outputs = sam(
pixel_values=inputs["pixel_values"],
input_boxes=inputs["input_boxes"],
multimask_output=False,
training=True,
)
predicted_masks = tf.squeeze(outputs.pred_masks, 1)
ground_truth_masks = tf.cast(inputs["ground_truth_mask"], tf.float32)
# calculate loss over predicted and ground truth masks
loss = dice_loss(tf.expand_dims(ground_truth_masks, 1), predicted_masks)
# update trainable variables
trainable_vars = sam.trainable_variables
grads = tape.gradient(loss, trainable_vars)
optimizer.apply_gradients(zip(grads, trainable_vars))
return loss
All model checkpoint layers were used when initializing TFSamModel.
All the layers of TFSamModel were initialized from the model checkpoint at facebook/sam-vit-base.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFSamModel for predictions without further training.
WARNING:absl:At this time, the v2.11+ optimizer [`tf.keras.optimizers.Adam`](https://tensorflowcn.cn/api_docs/python/tf/keras/optimizers/Adam) runs slowly on M1/M2 Macs, please use the legacy Keras optimizer instead, located at [`tf.keras.optimizers.legacy.Adam`](https://tensorflowcn.cn/api_docs/python/tf/keras/optimizers/legacy/Adam).
现在我们可以运行三个 epoch 的训练。可能会出现关于掩码解码器的 IoU 预测头不存在梯度的警告,我们可以安全地忽略它。
# run training
for epoch in range(3):
for inputs in train_ds:
loss = train_step(inputs)
print(f"Epoch {epoch + 1}: Loss = {loss}")
WARNING:tensorflow:Gradients do not exist for variables ['tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
WARNING:tensorflow:Gradients do not exist for variables ['tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
WARNING:tensorflow:Gradients do not exist for variables ['tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
WARNING:tensorflow:Gradients do not exist for variables ['tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
WARNING:tensorflow:Gradients do not exist for variables ['tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
WARNING:tensorflow:Gradients do not exist for variables ['tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
WARNING:tensorflow:Gradients do not exist for variables ['tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
WARNING:tensorflow:Gradients do not exist for variables ['tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_in/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/proj_out/bias:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/kernel:0', 'tf_sam_model_1/mask_decoder/iou_prediction_head/layers_._0/bias:0'] when minimizing the loss. If you're using `model.compile()`, did you forget to provide a `loss` argument?
Epoch 1: Loss = 0.08322787284851074
Epoch 2: Loss = 0.05677264928817749
Epoch 3: Loss = 0.07764029502868652
序列化模型
我们已将模型序列化并推送如下。push_to_hub 方法序列化模型,生成模型卡,并将其推送到 Hugging Face Hub,以便其他人可以使用 from_pretrained 方法加载模型进行推理或进一步微调。我们还需要将相同的预处理器推送到仓库中。在此处找到模型和预处理器。
# sam.push_to_hub("merve/sam-finetuned")
# processor.push_to_hub("merve/sam-finetuned")
现在我们可以使用模型进行推理。
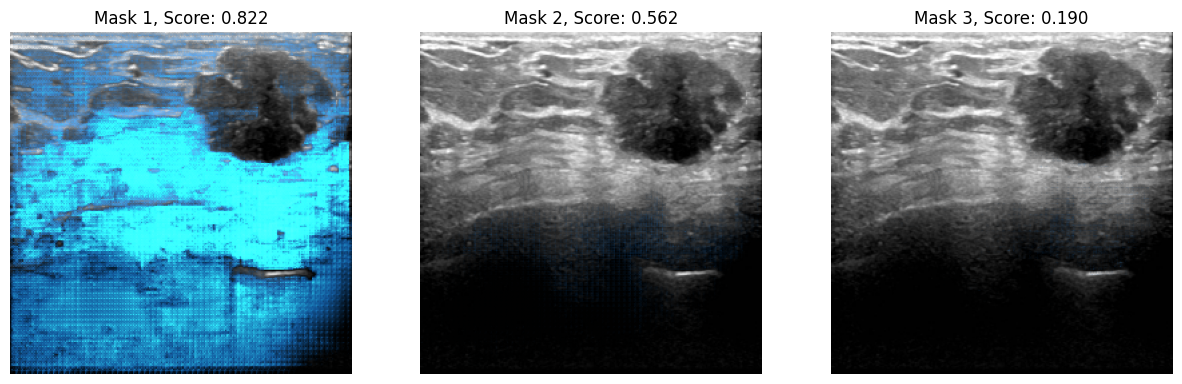
# Load another image for inference.
idx = 20
raw_image_inference = Image.open(image_paths[idx])
# process the image and infer
preprocessed_img = processor(raw_image_inference)
outputs = sam(preprocessed_img)
最后,我们可以可视化结果。
infer_masks = outputs["pred_masks"]
iou_scores = outputs["iou_scores"]
show_masks_on_image(raw_image_inference, masks=infer_masks, scores=iou_scores)
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).