使用MIRNet进行低光图像增强
作者: Soumik Rakshit
创建日期 2021/09/11
最后修改日期 2023/07/15
描述: 实现MIRNet架构以增强低光图像。

简介
为了从退化版本中恢复高质量图像内容,图像恢复技术在摄影、安全、医学成像和遥感等领域拥有众多应用。在本例中,我们实现了用于低光图像增强的MIRNet模型,这是一种全卷积架构,它学习一组丰富的特征,将多尺度的上下文信息结合起来,同时保留高分辨率的空间细节。
参考文献
下载LoL数据集
LoL Dataset是为了低光图像增强而创建的。它提供了485张用于训练的图像和15张用于测试的图像。数据集中每对图像包含一张低光输入图像及其对应的曝光良好的参考图像。
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import random
import numpy as np
from glob import glob
from PIL import Image, ImageOps
import matplotlib.pyplot as plt
import keras
from keras import layers
import tensorflow as tf
!wget https://huggingface.co/datasets/geekyrakshit/LoL-Dataset/resolve/main/lol_dataset.zip
!unzip -q lol_dataset.zip && rm lol_dataset.zip
--2023-11-10 23:10:00-- https://hugging-face.cn/datasets/geekyrakshit/LoL-Dataset/resolve/main/lol_dataset.zip
Resolving huggingface.co (huggingface.co)... 3.163.189.74, 3.163.189.37, 3.163.189.114, ...
Connecting to huggingface.co (huggingface.co)|3.163.189.74|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://cdn-lfs.huggingface.co/repos/d9/09/d909ef7668bb417b7065a311bd55a3084cc83a1f918e13cb41c5503328432db2/419fddc48958cd0f5599939ee0248852a37ceb8bb738c9b9525e95b25a89de9a?response-content-disposition=attachment%3B+filename*%3DUTF-8%27%27lol_dataset.zip%3B+filename%3D%22lol_dataset.zip%22%3B&response-content-type=application%2Fzip&Expires=1699917000&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTY5OTkxNzAwMH19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy5odWdnaW5nZmFjZS5jby9yZXBvcy9kOS8wOS9kOTA5ZWY3NjY4YmI0MTdiNzA2NWEzMTFiZDU1YTMwODRjYzgzYTFmOTE4ZTEzY2I0MWM1NTAzMzI4NDMyZGIyLzQxOWZkZGM0ODk1OGNkMGY1NTk5OTM5ZWUwMjQ4ODUyYTM3Y2ViOGJiNzM4YzliOTUyNWU5NWIyNWE4OWRlOWE%7EcmVzcG9uc2UtY29udGVudC1kaXNwb3NpdGlvbj0qJnJlc3BvbnNlLWNvbnRlbnQtdHlwZT0qIn1dfQ__&Signature=xyZ1oUBOnWdy6-vCAFzqZsDMetsPu6OSluyOoTS%7EKRZ6lvAy8yUwQgp5WjcZGJ7Jnex0IdnsPiUzsxaxjM-eZjUcQGPdGj4WhSV5DUBxr8xkwTEospYSg1fX%7EE2I1KkP9gBsXvinsKIOAZzchbg9f28xxdlvTbZ0h4ndcUfbDPknwlU1CIZNa5qjU6NqLMH2bPQmI1AIVau2DgQC%7E1n2dgTZsMfHTVmoM2ivsAl%7E9XgQ3m247ke2aj5BmgssZF52VWKTE-vwYDtbuiem73pS6gS-dZlmXYPE1OSRr2tsDo1cgPEBBtuK3hEnYcOq8jjEZk3AEAbFAJoHKLVIERZ30g__&Key-Pair-Id=KVTP0A1DKRTAX [following]
--2023-11-10 23:10:00-- https://cdn-lfs.huggingface.co/repos/d9/09/d909ef7668bb417b7065a311bd55a3084cc83a1f918e13cb41c5503328432db2/419fddc48958cd0f5599939ee0248852a37ceb8bb738c9b9525e95b25a89de9a?response-content-disposition=attachment%3B+filename*%3DUTF-8%27%27lol_dataset.zip%3B+filename%3D%22lol_dataset.zip%22%3B&response-content-type=application%2Fzip&Expires=1699917000&Policy=eyJTdGF0ZW1lbnQiOlt7IkNvbmRpdGlvbiI6eyJEYXRlTGVzc1RoYW4iOnsiQVdTOkVwb2NoVGltZSI6MTY5OTkxNzAwMH19LCJSZXNvdXJjZSI6Imh0dHBzOi8vY2RuLWxmcy5odWdnaW5nZmFjZS5jby9yZXBvcy9kOS8wOS9kOTA5ZWY3NjY4YmI0MTdiNzA2NWEzMTFiZDU1YTMwODRjYzgzYTFmOTE4ZTEzY2I0MWM1NTAzMzI4NDMyZGIyLzQxOWZkZGM0ODk1OGNkMGY1NTk5OTM5ZWUwMjQ4ODUyYTM3Y2ViOGJiNzM4YzliOTUyNWU5NWIyNWE4OWRlOWE%7EcmVzcG9uc2UtY29udGVudC1kaXNwb3NpdGlvbj0qJnJlc3BvbnNlLWNvbnRlbnQtdHlwZT0qIn1dfQ__&Signature=xyZ1oUBOnWdy6-vCAFzqZsDMetsPu6OSluyOoTS%7EKRZ6lvAy8yUwQgp5WjcZGJ7Jnex0IdnsPiUzsxaxjM-eZjUcQGPdGj4WhSV5DUBxr8xkwTEospYSg1fX%7EE2I1KkP9gBsXvinsKIOAZzchbg9f28xxdlvTbZ0h4ndcUfbDPknwlU1CIZNa5qjU6NqLMH2bPQmI1AIVau2DgQC%7E1n2dgTZsMfHTVmoM2ivsAl%7E9XgQ3m247ke2aj5BmgssZF52VWKTE-vwYDtbuiem73pS6gS-dZlmXYPE1OSRr2tsDo1cgPEBBtuK3hEnYcOq8jjEZk3AEAbFAJoHKLVIERZ30g__&Key-Pair-Id=KVTP0A1DKRTAX
Resolving cdn-lfs.huggingface.co (cdn-lfs.huggingface.co)... 108.138.94.122, 108.138.94.14, 108.138.94.25, ...
Connecting to cdn-lfs.huggingface.co (cdn-lfs.huggingface.co)|108.138.94.122|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 347171015 (331M) [application/zip]
Saving to: ‘lol_dataset.zip’
lol_dataset.zip 100%[===================>] 331.09M 316MB/s in 1.0s
2023-11-10 23:10:01 (316 MB/s) - ‘lol_dataset.zip’ saved [347171015/347171015]
创建 TensorFlow 数据集
我们使用LoL数据集训练集中的300张图像对进行训练,并使用剩余的185张图像对进行验证。我们从图像对中生成大小为128 x 128的随机裁剪图像,用于训练和验证。
random.seed(10)
IMAGE_SIZE = 128
BATCH_SIZE = 4
MAX_TRAIN_IMAGES = 300
def read_image(image_path):
image = tf.io.read_file(image_path)
image = tf.image.decode_png(image, channels=3)
image.set_shape([None, None, 3])
image = tf.cast(image, dtype=tf.float32) / 255.0
return image
def random_crop(low_image, enhanced_image):
low_image_shape = tf.shape(low_image)[:2]
low_w = tf.random.uniform(
shape=(), maxval=low_image_shape[1] - IMAGE_SIZE + 1, dtype=tf.int32
)
low_h = tf.random.uniform(
shape=(), maxval=low_image_shape[0] - IMAGE_SIZE + 1, dtype=tf.int32
)
low_image_cropped = low_image[
low_h : low_h + IMAGE_SIZE, low_w : low_w + IMAGE_SIZE
]
enhanced_image_cropped = enhanced_image[
low_h : low_h + IMAGE_SIZE, low_w : low_w + IMAGE_SIZE
]
# in order to avoid `NONE` during shape inference
low_image_cropped.set_shape([IMAGE_SIZE, IMAGE_SIZE, 3])
enhanced_image_cropped.set_shape([IMAGE_SIZE, IMAGE_SIZE, 3])
return low_image_cropped, enhanced_image_cropped
def load_data(low_light_image_path, enhanced_image_path):
low_light_image = read_image(low_light_image_path)
enhanced_image = read_image(enhanced_image_path)
low_light_image, enhanced_image = random_crop(low_light_image, enhanced_image)
return low_light_image, enhanced_image
def get_dataset(low_light_images, enhanced_images):
dataset = tf.data.Dataset.from_tensor_slices((low_light_images, enhanced_images))
dataset = dataset.map(load_data, num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
return dataset
train_low_light_images = sorted(glob("./lol_dataset/our485/low/*"))[:MAX_TRAIN_IMAGES]
train_enhanced_images = sorted(glob("./lol_dataset/our485/high/*"))[:MAX_TRAIN_IMAGES]
val_low_light_images = sorted(glob("./lol_dataset/our485/low/*"))[MAX_TRAIN_IMAGES:]
val_enhanced_images = sorted(glob("./lol_dataset/our485/high/*"))[MAX_TRAIN_IMAGES:]
test_low_light_images = sorted(glob("./lol_dataset/eval15/low/*"))
test_enhanced_images = sorted(glob("./lol_dataset/eval15/high/*"))
train_dataset = get_dataset(train_low_light_images, train_enhanced_images)
val_dataset = get_dataset(val_low_light_images, val_enhanced_images)
print("Train Dataset:", train_dataset.element_spec)
print("Val Dataset:", val_dataset.element_spec)
Train Dataset: (TensorSpec(shape=(4, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(4, 128, 128, 3), dtype=tf.float32, name=None))
Val Dataset: (TensorSpec(shape=(4, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(4, 128, 128, 3), dtype=tf.float32, name=None))
MIRNet模型
MIRNet模型的主要特点如下:
- 一个特征提取模型,它在多个空间尺度上计算一组丰富的互补特征,同时保持原始高分辨率特征以保留精确的空间细节。
- 一个定期重复的信息交换机制,其中多分辨率分支之间的特征逐渐融合,以提高表示学习能力。
- 一种使用选择性核网络融合多尺度特征的新方法,该网络动态地组合不同的感受野,并忠实地保留每个空间分辨率上的原始特征信息。
- 一种递归残差设计,它逐步分解输入信号,以简化整个学习过程,并允许构建非常深的网络。
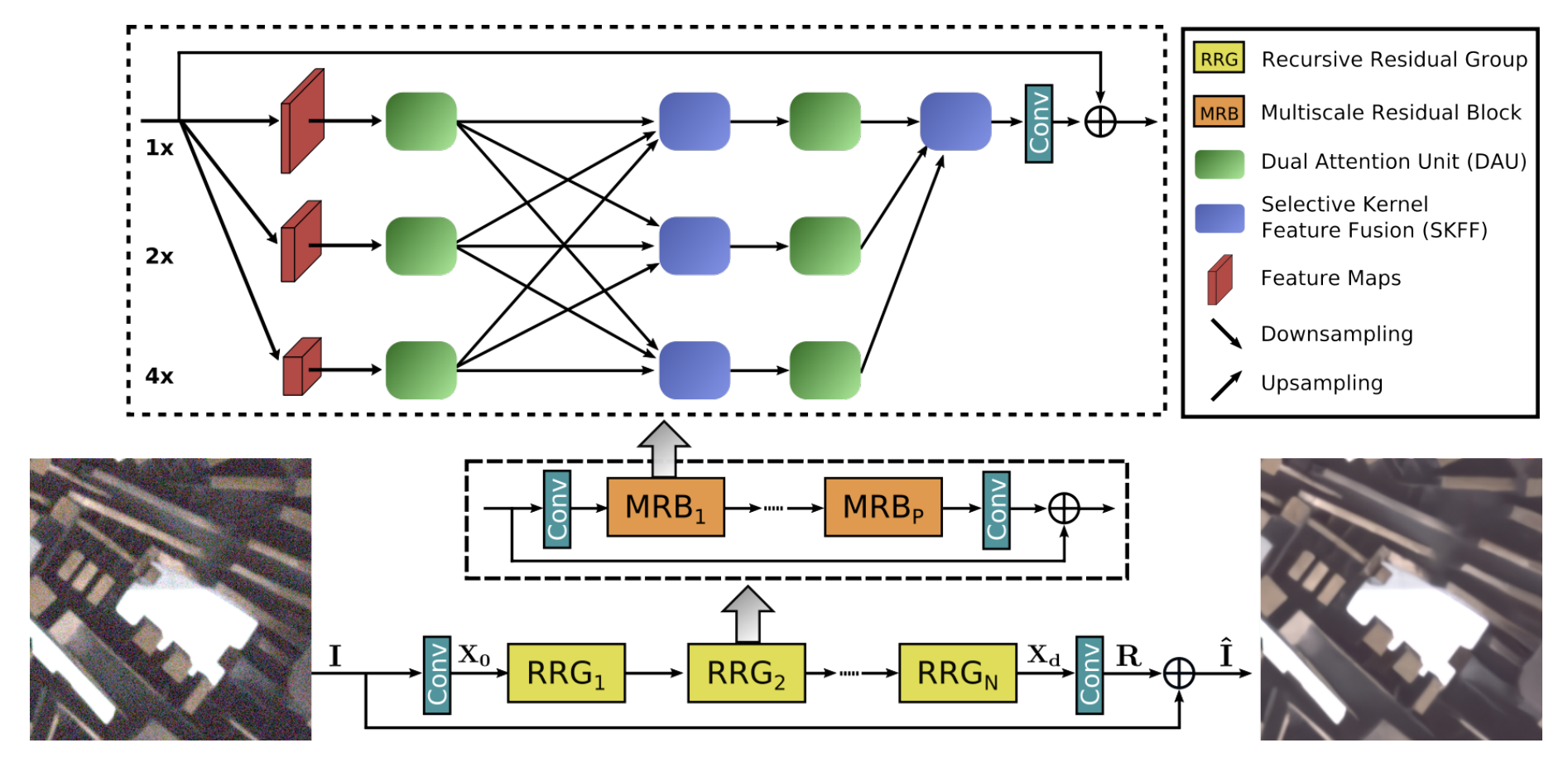
选择性核特征融合
选择性核特征融合(SKFF)模块通过两种操作:融合和选择,对感受野进行动态调整。融合操作通过组合多分辨率流的信息来生成全局特征描述符。选择操作使用这些描述符来重新校准(不同流的)特征图,然后进行聚合。
融合:SKFF接收来自三个并行卷积流的输入,这些流携带不同尺度的信息。我们首先使用逐元素求和来组合这些多尺度特征,然后对该特征应用空间维度的全局平均池化(GAP)。接下来,我们应用一个通道下采样卷积层来生成紧凑的特征表示,该表示通过三个并行通道上采样卷积层(每个分辨率流一个)并为我们提供三个特征描述符。
选择:该操作将softmax函数应用于特征描述符,以获得相应的激活,这些激活用于自适应地重新校准多尺度特征图。聚合特征被定义为相应多尺度特征与特征描述符的乘积之和。

def selective_kernel_feature_fusion(
multi_scale_feature_1, multi_scale_feature_2, multi_scale_feature_3
):
channels = list(multi_scale_feature_1.shape)[-1]
combined_feature = layers.Add()(
[multi_scale_feature_1, multi_scale_feature_2, multi_scale_feature_3]
)
gap = layers.GlobalAveragePooling2D()(combined_feature)
channel_wise_statistics = layers.Reshape((1, 1, channels))(gap)
compact_feature_representation = layers.Conv2D(
filters=channels // 8, kernel_size=(1, 1), activation="relu"
)(channel_wise_statistics)
feature_descriptor_1 = layers.Conv2D(
channels, kernel_size=(1, 1), activation="softmax"
)(compact_feature_representation)
feature_descriptor_2 = layers.Conv2D(
channels, kernel_size=(1, 1), activation="softmax"
)(compact_feature_representation)
feature_descriptor_3 = layers.Conv2D(
channels, kernel_size=(1, 1), activation="softmax"
)(compact_feature_representation)
feature_1 = multi_scale_feature_1 * feature_descriptor_1
feature_2 = multi_scale_feature_2 * feature_descriptor_2
feature_3 = multi_scale_feature_3 * feature_descriptor_3
aggregated_feature = layers.Add()([feature_1, feature_2, feature_3])
return aggregated_feature
双注意力单元
双注意力单元(DAU)用于提取卷积流中的特征。虽然SKFF块跨多分辨率分支融合信息,但我们也需要一种机制来在空间和通道维度上共享特征张量内的信息,这是DAU块完成的。DAU抑制不太有用的特征,只允许更有信息量的特征进一步传递。这种特征重新校准是通过使用通道注意力和空间注意力机制来实现的。
通道注意力分支通过应用挤压和激励操作来利用卷积特征图的通道间关系。给定一个特征图,挤压操作在空间维度上应用全局平均池化来编码全局上下文,从而生成一个特征描述符。激励算子将此特征描述符通过两个卷积层,然后进行sigmoid门控,生成激活。最后,通过用输出激活重新缩放输入特征图来获得通道注意力分支的输出。
空间注意力分支旨在利用卷积特征的空间依赖性。空间注意力的目标是生成一个空间注意力图,并使用它来重新校准输入特征。为了生成空间注意力图,空间注意力分支首先独立地在输入特征上沿通道维度应用全局平均池化和最大池化操作,然后将输出连接起来形成一个结果特征图,该特征图随后通过卷积和sigmoid激活以获得空间注意力图。然后,使用此空间注意力图来重新缩放输入特征图。

class ChannelPooling(layers.Layer):
def __init__(self, axis=-1, *args, **kwargs):
super().__init__(*args, **kwargs)
self.axis = axis
self.concat = layers.Concatenate(axis=self.axis)
def call(self, inputs):
average_pooling = tf.expand_dims(tf.reduce_mean(inputs, axis=-1), axis=-1)
max_pooling = tf.expand_dims(tf.reduce_max(inputs, axis=-1), axis=-1)
return self.concat([average_pooling, max_pooling])
def get_config(self):
config = super().get_config()
config.update({"axis": self.axis})
def spatial_attention_block(input_tensor):
compressed_feature_map = ChannelPooling(axis=-1)(input_tensor)
feature_map = layers.Conv2D(1, kernel_size=(1, 1))(compressed_feature_map)
feature_map = keras.activations.sigmoid(feature_map)
return input_tensor * feature_map
def channel_attention_block(input_tensor):
channels = list(input_tensor.shape)[-1]
average_pooling = layers.GlobalAveragePooling2D()(input_tensor)
feature_descriptor = layers.Reshape((1, 1, channels))(average_pooling)
feature_activations = layers.Conv2D(
filters=channels // 8, kernel_size=(1, 1), activation="relu"
)(feature_descriptor)
feature_activations = layers.Conv2D(
filters=channels, kernel_size=(1, 1), activation="sigmoid"
)(feature_activations)
return input_tensor * feature_activations
def dual_attention_unit_block(input_tensor):
channels = list(input_tensor.shape)[-1]
feature_map = layers.Conv2D(
channels, kernel_size=(3, 3), padding="same", activation="relu"
)(input_tensor)
feature_map = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(
feature_map
)
channel_attention = channel_attention_block(feature_map)
spatial_attention = spatial_attention_block(feature_map)
concatenation = layers.Concatenate(axis=-1)([channel_attention, spatial_attention])
concatenation = layers.Conv2D(channels, kernel_size=(1, 1))(concatenation)
return layers.Add()([input_tensor, concatenation])
多尺度残差块
多尺度残差块(MRB)通过保持高分辨率表示来生成空间精确的输出,同时从低分辨率接收丰富的上下文信息。MRB由三个(本文中)并行连接的全卷积流组成。它允许并行流之间的信息交换,以在低分辨率特征的帮助下巩固高分辨率特征,反之亦然。MIRNet采用递归残差设计(带跳跃连接),以在学习过程中简化信息流。为了保持我们架构的残差性质,使用残差重缩放模块来执行多尺度残差块中使用的下采样和上采样操作。

# Recursive Residual Modules
def down_sampling_module(input_tensor):
channels = list(input_tensor.shape)[-1]
main_branch = layers.Conv2D(channels, kernel_size=(1, 1), activation="relu")(
input_tensor
)
main_branch = layers.Conv2D(
channels, kernel_size=(3, 3), padding="same", activation="relu"
)(main_branch)
main_branch = layers.MaxPooling2D()(main_branch)
main_branch = layers.Conv2D(channels * 2, kernel_size=(1, 1))(main_branch)
skip_branch = layers.MaxPooling2D()(input_tensor)
skip_branch = layers.Conv2D(channels * 2, kernel_size=(1, 1))(skip_branch)
return layers.Add()([skip_branch, main_branch])
def up_sampling_module(input_tensor):
channels = list(input_tensor.shape)[-1]
main_branch = layers.Conv2D(channels, kernel_size=(1, 1), activation="relu")(
input_tensor
)
main_branch = layers.Conv2D(
channels, kernel_size=(3, 3), padding="same", activation="relu"
)(main_branch)
main_branch = layers.UpSampling2D()(main_branch)
main_branch = layers.Conv2D(channels // 2, kernel_size=(1, 1))(main_branch)
skip_branch = layers.UpSampling2D()(input_tensor)
skip_branch = layers.Conv2D(channels // 2, kernel_size=(1, 1))(skip_branch)
return layers.Add()([skip_branch, main_branch])
# MRB Block
def multi_scale_residual_block(input_tensor, channels):
# features
level1 = input_tensor
level2 = down_sampling_module(input_tensor)
level3 = down_sampling_module(level2)
# DAU
level1_dau = dual_attention_unit_block(level1)
level2_dau = dual_attention_unit_block(level2)
level3_dau = dual_attention_unit_block(level3)
# SKFF
level1_skff = selective_kernel_feature_fusion(
level1_dau,
up_sampling_module(level2_dau),
up_sampling_module(up_sampling_module(level3_dau)),
)
level2_skff = selective_kernel_feature_fusion(
down_sampling_module(level1_dau),
level2_dau,
up_sampling_module(level3_dau),
)
level3_skff = selective_kernel_feature_fusion(
down_sampling_module(down_sampling_module(level1_dau)),
down_sampling_module(level2_dau),
level3_dau,
)
# DAU 2
level1_dau_2 = dual_attention_unit_block(level1_skff)
level2_dau_2 = up_sampling_module((dual_attention_unit_block(level2_skff)))
level3_dau_2 = up_sampling_module(
up_sampling_module(dual_attention_unit_block(level3_skff))
)
# SKFF 2
skff_ = selective_kernel_feature_fusion(level1_dau_2, level2_dau_2, level3_dau_2)
conv = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(skff_)
return layers.Add()([input_tensor, conv])
MIRNet模型
def recursive_residual_group(input_tensor, num_mrb, channels):
conv1 = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(input_tensor)
for _ in range(num_mrb):
conv1 = multi_scale_residual_block(conv1, channels)
conv2 = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(conv1)
return layers.Add()([conv2, input_tensor])
def mirnet_model(num_rrg, num_mrb, channels):
input_tensor = keras.Input(shape=[None, None, 3])
x1 = layers.Conv2D(channels, kernel_size=(3, 3), padding="same")(input_tensor)
for _ in range(num_rrg):
x1 = recursive_residual_group(x1, num_mrb, channels)
conv = layers.Conv2D(3, kernel_size=(3, 3), padding="same")(x1)
output_tensor = layers.Add()([input_tensor, conv])
return keras.Model(input_tensor, output_tensor)
model = mirnet_model(num_rrg=3, num_mrb=2, channels=64)
训练
- 我们使用Charbonnier损失作为损失函数,并使用Adam优化器,学习率为
1e-4来训练MIRNet。 - 我们使用峰值信噪比(PSNR)作为度量。PSNR是信号最大可能值(功率)与影响其表示质量的噪声功率之间的比率的表达式。
def charbonnier_loss(y_true, y_pred):
return tf.reduce_mean(tf.sqrt(tf.square(y_true - y_pred) + tf.square(1e-3)))
def peak_signal_noise_ratio(y_true, y_pred):
return tf.image.psnr(y_pred, y_true, max_val=255.0)
optimizer = keras.optimizers.Adam(learning_rate=1e-4)
model.compile(
optimizer=optimizer,
loss=charbonnier_loss,
metrics=[peak_signal_noise_ratio],
)
history = model.fit(
train_dataset,
validation_data=val_dataset,
epochs=50,
callbacks=[
keras.callbacks.ReduceLROnPlateau(
monitor="val_peak_signal_noise_ratio",
factor=0.5,
patience=5,
verbose=1,
min_delta=1e-7,
mode="max",
)
],
)
def plot_history(value, name):
plt.plot(history.history[value], label=f"train_{name.lower()}")
plt.plot(history.history[f"val_{value}"], label=f"val_{name.lower()}")
plt.xlabel("Epochs")
plt.ylabel(name)
plt.title(f"Train and Validation {name} Over Epochs", fontsize=14)
plt.legend()
plt.grid()
plt.show()
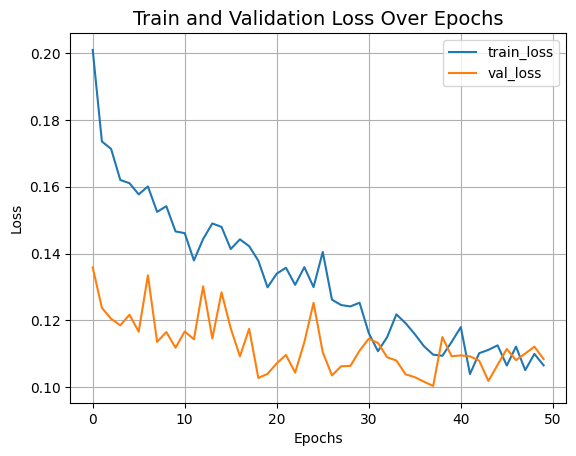
plot_history("loss", "Loss")
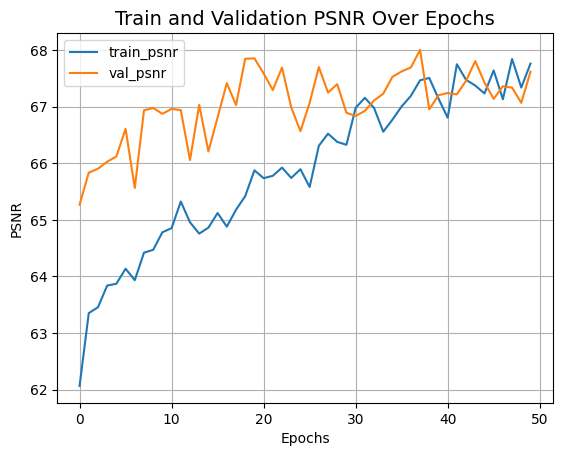
plot_history("peak_signal_noise_ratio", "PSNR")
Epoch 1/50
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1699658204.480352 77759 device_compiler.h:187] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
75/75 ━━━━━━━━━━━━━━━━━━━━ 445s 686ms/step - loss: 0.2162 - peak_signal_noise_ratio: 61.5549 - val_loss: 0.1358 - val_peak_signal_noise_ratio: 65.2699 - learning_rate: 1.0000e-04
Epoch 2/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 385ms/step - loss: 0.1745 - peak_signal_noise_ratio: 63.1785 - val_loss: 0.1237 - val_peak_signal_noise_ratio: 65.8360 - learning_rate: 1.0000e-04
Epoch 3/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 386ms/step - loss: 0.1681 - peak_signal_noise_ratio: 63.4903 - val_loss: 0.1205 - val_peak_signal_noise_ratio: 65.9048 - learning_rate: 1.0000e-04
Epoch 4/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 385ms/step - loss: 0.1668 - peak_signal_noise_ratio: 63.4793 - val_loss: 0.1185 - val_peak_signal_noise_ratio: 66.0290 - learning_rate: 1.0000e-04
Epoch 5/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 383ms/step - loss: 0.1564 - peak_signal_noise_ratio: 63.9205 - val_loss: 0.1217 - val_peak_signal_noise_ratio: 66.1207 - learning_rate: 1.0000e-04
Epoch 6/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 384ms/step - loss: 0.1601 - peak_signal_noise_ratio: 63.9336 - val_loss: 0.1166 - val_peak_signal_noise_ratio: 66.6102 - learning_rate: 1.0000e-04
Epoch 7/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 385ms/step - loss: 0.1600 - peak_signal_noise_ratio: 63.9043 - val_loss: 0.1335 - val_peak_signal_noise_ratio: 65.5639 - learning_rate: 1.0000e-04
Epoch 8/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 382ms/step - loss: 0.1609 - peak_signal_noise_ratio: 64.0606 - val_loss: 0.1135 - val_peak_signal_noise_ratio: 66.9369 - learning_rate: 1.0000e-04
Epoch 9/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 384ms/step - loss: 0.1539 - peak_signal_noise_ratio: 64.3915 - val_loss: 0.1165 - val_peak_signal_noise_ratio: 66.9783 - learning_rate: 1.0000e-04
Epoch 10/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 43s 409ms/step - loss: 0.1536 - peak_signal_noise_ratio: 64.4491 - val_loss: 0.1118 - val_peak_signal_noise_ratio: 66.8747 - learning_rate: 1.0000e-04
Epoch 11/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 383ms/step - loss: 0.1449 - peak_signal_noise_ratio: 64.6579 - val_loss: 0.1167 - val_peak_signal_noise_ratio: 66.9626 - learning_rate: 1.0000e-04
Epoch 12/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 383ms/step - loss: 0.1501 - peak_signal_noise_ratio: 64.7929 - val_loss: 0.1143 - val_peak_signal_noise_ratio: 66.9400 - learning_rate: 1.0000e-04
Epoch 13/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 380ms/step - loss: 0.1510 - peak_signal_noise_ratio: 64.6816 - val_loss: 0.1302 - val_peak_signal_noise_ratio: 66.0576 - learning_rate: 1.0000e-04
Epoch 14/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 383ms/step - loss: 0.1632 - peak_signal_noise_ratio: 63.9234 - val_loss: 0.1146 - val_peak_signal_noise_ratio: 67.0321 - learning_rate: 1.0000e-04
Epoch 15/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 379ms/step - loss: 0.1486 - peak_signal_noise_ratio: 64.7125 - val_loss: 0.1284 - val_peak_signal_noise_ratio: 66.2105 - learning_rate: 1.0000e-04
Epoch 16/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 379ms/step - loss: 0.1482 - peak_signal_noise_ratio: 64.8123 - val_loss: 0.1176 - val_peak_signal_noise_ratio: 66.8114 - learning_rate: 1.0000e-04
Epoch 17/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 381ms/step - loss: 0.1459 - peak_signal_noise_ratio: 64.7795 - val_loss: 0.1092 - val_peak_signal_noise_ratio: 67.4173 - learning_rate: 1.0000e-04
Epoch 18/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 378ms/step - loss: 0.1482 - peak_signal_noise_ratio: 64.8821 - val_loss: 0.1175 - val_peak_signal_noise_ratio: 67.0296 - learning_rate: 1.0000e-04
Epoch 19/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 381ms/step - loss: 0.1524 - peak_signal_noise_ratio: 64.7275 - val_loss: 0.1028 - val_peak_signal_noise_ratio: 67.8485 - learning_rate: 1.0000e-04
Epoch 20/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 379ms/step - loss: 0.1350 - peak_signal_noise_ratio: 65.6166 - val_loss: 0.1040 - val_peak_signal_noise_ratio: 67.8551 - learning_rate: 1.0000e-04
Epoch 21/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 380ms/step - loss: 0.1383 - peak_signal_noise_ratio: 65.5167 - val_loss: 0.1071 - val_peak_signal_noise_ratio: 67.5902 - learning_rate: 1.0000e-04
Epoch 22/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 379ms/step - loss: 0.1393 - peak_signal_noise_ratio: 65.6293 - val_loss: 0.1096 - val_peak_signal_noise_ratio: 67.2940 - learning_rate: 1.0000e-04
Epoch 23/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 383ms/step - loss: 0.1399 - peak_signal_noise_ratio: 65.5146 - val_loss: 0.1044 - val_peak_signal_noise_ratio: 67.6932 - learning_rate: 1.0000e-04
Epoch 24/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 378ms/step - loss: 0.1390 - peak_signal_noise_ratio: 65.7525 - val_loss: 0.1135 - val_peak_signal_noise_ratio: 66.9891 - learning_rate: 1.0000e-04
Epoch 25/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 0s 326ms/step - loss: 0.1333 - peak_signal_noise_ratio: 65.8340
Epoch 25: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-05.
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 380ms/step - loss: 0.1332 - peak_signal_noise_ratio: 65.8348 - val_loss: 0.1252 - val_peak_signal_noise_ratio: 66.5684 - learning_rate: 1.0000e-04
Epoch 26/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 381ms/step - loss: 0.1547 - peak_signal_noise_ratio: 64.8968 - val_loss: 0.1105 - val_peak_signal_noise_ratio: 67.0688 - learning_rate: 5.0000e-05
Epoch 27/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 380ms/step - loss: 0.1269 - peak_signal_noise_ratio: 66.3882 - val_loss: 0.1035 - val_peak_signal_noise_ratio: 67.7006 - learning_rate: 5.0000e-05
Epoch 28/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 30s 405ms/step - loss: 0.1243 - peak_signal_noise_ratio: 66.5826 - val_loss: 0.1063 - val_peak_signal_noise_ratio: 67.2497 - learning_rate: 5.0000e-05
Epoch 29/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 383ms/step - loss: 0.1292 - peak_signal_noise_ratio: 66.1734 - val_loss: 0.1064 - val_peak_signal_noise_ratio: 67.3989 - learning_rate: 5.0000e-05
Epoch 30/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 0s 328ms/step - loss: 0.1304 - peak_signal_noise_ratio: 66.1267
Epoch 30: ReduceLROnPlateau reducing learning rate to 2.499999936844688e-05.
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 382ms/step - loss: 0.1304 - peak_signal_noise_ratio: 66.1294 - val_loss: 0.1109 - val_peak_signal_noise_ratio: 66.8935 - learning_rate: 5.0000e-05
Epoch 31/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 381ms/step - loss: 0.1141 - peak_signal_noise_ratio: 67.1338 - val_loss: 0.1145 - val_peak_signal_noise_ratio: 66.8367 - learning_rate: 2.5000e-05
Epoch 32/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 380ms/step - loss: 0.1141 - peak_signal_noise_ratio: 66.9369 - val_loss: 0.1132 - val_peak_signal_noise_ratio: 66.9264 - learning_rate: 2.5000e-05
Epoch 33/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 380ms/step - loss: 0.1184 - peak_signal_noise_ratio: 66.7723 - val_loss: 0.1090 - val_peak_signal_noise_ratio: 67.1115 - learning_rate: 2.5000e-05
Epoch 34/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 380ms/step - loss: 0.1243 - peak_signal_noise_ratio: 66.4147 - val_loss: 0.1080 - val_peak_signal_noise_ratio: 67.2300 - learning_rate: 2.5000e-05
Epoch 35/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 0s 325ms/step - loss: 0.1230 - peak_signal_noise_ratio: 66.7113
Epoch 35: ReduceLROnPlateau reducing learning rate to 1.249999968422344e-05.
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 381ms/step - loss: 0.1229 - peak_signal_noise_ratio: 66.7121 - val_loss: 0.1038 - val_peak_signal_noise_ratio: 67.5288 - learning_rate: 2.5000e-05
Epoch 36/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 380ms/step - loss: 0.1181 - peak_signal_noise_ratio: 66.9202 - val_loss: 0.1030 - val_peak_signal_noise_ratio: 67.6249 - learning_rate: 1.2500e-05
Epoch 37/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 380ms/step - loss: 0.1086 - peak_signal_noise_ratio: 67.5034 - val_loss: 0.1016 - val_peak_signal_noise_ratio: 67.6940 - learning_rate: 1.2500e-05
Epoch 38/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 380ms/step - loss: 0.1127 - peak_signal_noise_ratio: 67.3735 - val_loss: 0.1004 - val_peak_signal_noise_ratio: 68.0042 - learning_rate: 1.2500e-05
Epoch 39/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 379ms/step - loss: 0.1135 - peak_signal_noise_ratio: 67.3436 - val_loss: 0.1150 - val_peak_signal_noise_ratio: 66.9541 - learning_rate: 1.2500e-05
Epoch 40/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 381ms/step - loss: 0.1152 - peak_signal_noise_ratio: 67.1675 - val_loss: 0.1093 - val_peak_signal_noise_ratio: 67.2030 - learning_rate: 1.2500e-05
Epoch 41/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 378ms/step - loss: 0.1191 - peak_signal_noise_ratio: 66.7586 - val_loss: 0.1095 - val_peak_signal_noise_ratio: 67.2424 - learning_rate: 1.2500e-05
Epoch 42/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 30s 405ms/step - loss: 0.1062 - peak_signal_noise_ratio: 67.6856 - val_loss: 0.1092 - val_peak_signal_noise_ratio: 67.2187 - learning_rate: 1.2500e-05
Epoch 43/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 0s 323ms/step - loss: 0.1099 - peak_signal_noise_ratio: 67.6400
Epoch 43: ReduceLROnPlateau reducing learning rate to 6.24999984211172e-06.
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 377ms/step - loss: 0.1099 - peak_signal_noise_ratio: 67.6378 - val_loss: 0.1079 - val_peak_signal_noise_ratio: 67.4591 - learning_rate: 1.2500e-05
Epoch 44/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 378ms/step - loss: 0.1155 - peak_signal_noise_ratio: 67.0911 - val_loss: 0.1019 - val_peak_signal_noise_ratio: 67.8073 - learning_rate: 6.2500e-06
Epoch 45/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 377ms/step - loss: 0.1145 - peak_signal_noise_ratio: 67.1876 - val_loss: 0.1067 - val_peak_signal_noise_ratio: 67.4283 - learning_rate: 6.2500e-06
Epoch 46/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 384ms/step - loss: 0.1077 - peak_signal_noise_ratio: 67.7168 - val_loss: 0.1114 - val_peak_signal_noise_ratio: 67.1392 - learning_rate: 6.2500e-06
Epoch 47/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 377ms/step - loss: 0.1117 - peak_signal_noise_ratio: 67.3210 - val_loss: 0.1081 - val_peak_signal_noise_ratio: 67.3622 - learning_rate: 6.2500e-06
Epoch 48/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 0s 326ms/step - loss: 0.1074 - peak_signal_noise_ratio: 67.7986
Epoch 48: ReduceLROnPlateau reducing learning rate to 3.12499992105586e-06.
75/75 ━━━━━━━━━━━━━━━━━━━━ 29s 380ms/step - loss: 0.1074 - peak_signal_noise_ratio: 67.7992 - val_loss: 0.1101 - val_peak_signal_noise_ratio: 67.3376 - learning_rate: 6.2500e-06
Epoch 49/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 380ms/step - loss: 0.1081 - peak_signal_noise_ratio: 67.5032 - val_loss: 0.1121 - val_peak_signal_noise_ratio: 67.0685 - learning_rate: 3.1250e-06
Epoch 50/50
75/75 ━━━━━━━━━━━━━━━━━━━━ 28s 378ms/step - loss: 0.1077 - peak_signal_noise_ratio: 67.6709 - val_loss: 0.1084 - val_peak_signal_noise_ratio: 67.6183 - learning_rate: 3.1250e-06
推理
def plot_results(images, titles, figure_size=(12, 12)):
fig = plt.figure(figsize=figure_size)
for i in range(len(images)):
fig.add_subplot(1, len(images), i + 1).set_title(titles[i])
_ = plt.imshow(images[i])
plt.axis("off")
plt.show()
def infer(original_image):
image = keras.utils.img_to_array(original_image)
image = image.astype("float32") / 255.0
image = np.expand_dims(image, axis=0)
output = model.predict(image, verbose=0)
output_image = output[0] * 255.0
output_image = output_image.clip(0, 255)
output_image = output_image.reshape(
(np.shape(output_image)[0], np.shape(output_image)[1], 3)
)
output_image = Image.fromarray(np.uint8(output_image))
original_image = Image.fromarray(np.uint8(original_image))
return output_image
在测试图像上进行推理
我们将MIRNet增强的LOLDataset中的测试图像与通过PIL.ImageOps.autocontrast()函数增强的图像进行比较。
您可以使用托管在Hugging Face Hub上的训练模型,并在Hugging Face Spaces上尝试演示。
for low_light_image in random.sample(test_low_light_images, 6):
original_image = Image.open(low_light_image)
enhanced_image = infer(original_image)
plot_results(
[original_image, ImageOps.autocontrast(original_image), enhanced_image],
["Original", "PIL Autocontrast", "MIRNet Enhanced"],
(20, 12),
)





