学习调整计算机视觉中的图像大小
作者:Sayak Paul
创建日期 2021/04/30
最后修改日期 2023/12/18
描述: 如何为给定分辨率最优地学习图像的表征。

人们普遍认为,如果我们限制视觉模型像人类一样感知事物,它们的性能可以得到提高。例如,在 这项工作中,Geirhos 等人表明,在 ImageNet-1k 数据集上预训练的视觉模型偏向于纹理,而人类主要使用形状描述符来形成共同的感知。但这种信念是否总是适用,尤其是在提高视觉模型的性能方面?
事实证明,情况可能并非总是如此。在训练视觉模型时,通常会(224 x 224)、(299 x 299)等)将图像调整到较低的分辨率,以便进行小批量学习,并保持在计算限制范围内。我们通常为此步骤使用图像调整大小的方法,如双线性插值,调整后的图像对人眼来说不会损失太多感知特征。在 Learning to Resize Images for Computer Vision Tasks 中,Talebi 等人表明,如果我们试图优化图像对视觉模型的感知质量而不是对人眼的感知质量,它们的性能可以得到进一步提高。他们调查了以下问题:
对于给定的图像分辨率和模型,如何最好地调整给定图像的大小?
正如论文所示,这个想法有助于持续提高常见视觉模型(在 ImageNet-1k 上预训练)如 DenseNet-121、ResNet-50、MobileNetV2 和 EfficientNets 的性能。在此示例中,我们将实现论文中提出的可学习图像调整大小模块,并在 猫狗数据集上使用 DenseNet-121 架构来演示这一点。
设置
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras
from keras import ops
from keras import layers
import tensorflow as tf
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
import matplotlib.pyplot as plt
import numpy as np
定义超参数
为了便于小批量学习,我们需要给定批次内的图像具有固定的形状。这就是为什么需要初始调整大小。我们首先将所有图像调整为 (300 x 300) 的形状,然后学习它们在 (150 x 150) 分辨率下的最优表示。
INP_SIZE = (300, 300)
TARGET_SIZE = (150, 150)
INTERPOLATION = "bilinear"
AUTO = tf.data.AUTOTUNE
BATCH_SIZE = 64
EPOCHS = 5
在此示例中,我们将使用双线性插值,但可学习的图像调整大小模块不依赖于任何特定的插值方法。我们也可以使用其他方法,例如双三次插值。
加载和准备数据集
在此示例中,我们将仅使用总训练数据集的 40%。
train_ds, validation_ds = tfds.load(
"cats_vs_dogs",
# Reserve 10% for validation
split=["train[:40%]", "train[40%:50%]"],
as_supervised=True,
)
def preprocess_dataset(image, label):
image = ops.image.resize(image, (INP_SIZE[0], INP_SIZE[1]))
label = ops.one_hot(label, num_classes=2)
return (image, label)
train_ds = (
train_ds.shuffle(BATCH_SIZE * 100)
.map(preprocess_dataset, num_parallel_calls=AUTO)
.batch(BATCH_SIZE)
.prefetch(AUTO)
)
validation_ds = (
validation_ds.map(preprocess_dataset, num_parallel_calls=AUTO)
.batch(BATCH_SIZE)
.prefetch(AUTO)
)
定义可学习调整大小工具
下图(来自:Learning to Resize Images for Computer Vision Tasks)展示了可学习调整大小模块的结构。

def conv_block(x, filters, kernel_size, strides, activation=layers.LeakyReLU(0.2)):
x = layers.Conv2D(filters, kernel_size, strides, padding="same", use_bias=False)(x)
x = layers.BatchNormalization()(x)
if activation:
x = activation(x)
return x
def res_block(x):
inputs = x
x = conv_block(x, 16, 3, 1)
x = conv_block(x, 16, 3, 1, activation=None)
return layers.Add()([inputs, x])
# Note: user can change num_res_blocks to >1 also if needed
def get_learnable_resizer(filters=16, num_res_blocks=1, interpolation=INTERPOLATION):
inputs = layers.Input(shape=[None, None, 3])
# First, perform naive resizing.
naive_resize = layers.Resizing(*TARGET_SIZE, interpolation=interpolation)(inputs)
# First convolution block without batch normalization.
x = layers.Conv2D(filters=filters, kernel_size=7, strides=1, padding="same")(inputs)
x = layers.LeakyReLU(0.2)(x)
# Second convolution block with batch normalization.
x = layers.Conv2D(filters=filters, kernel_size=1, strides=1, padding="same")(x)
x = layers.LeakyReLU(0.2)(x)
x = layers.BatchNormalization()(x)
# Intermediate resizing as a bottleneck.
bottleneck = layers.Resizing(*TARGET_SIZE, interpolation=interpolation)(x)
# Residual passes.
# First res_block will get bottleneck output as input
x = res_block(bottleneck)
# Remaining res_blocks will get previous res_block output as input
for _ in range(num_res_blocks - 1):
x = res_block(x)
# Projection.
x = layers.Conv2D(
filters=filters, kernel_size=3, strides=1, padding="same", use_bias=False
)(x)
x = layers.BatchNormalization()(x)
# Skip connection.
x = layers.Add()([bottleneck, x])
# Final resized image.
x = layers.Conv2D(filters=3, kernel_size=7, strides=1, padding="same")(x)
final_resize = layers.Add()([naive_resize, x])
return keras.Model(inputs, final_resize, name="learnable_resizer")
learnable_resizer = get_learnable_resizer()
可视化可学习调整大小模块的输出
在这里,我们可视化图像通过调整大小器的随机权重后会是什么样子。
sample_images, _ = next(iter(train_ds))
plt.figure(figsize=(16, 10))
for i, image in enumerate(sample_images[:6]):
image = image / 255
ax = plt.subplot(3, 4, 2 * i + 1)
plt.title("Input Image")
plt.imshow(image.numpy().squeeze())
plt.axis("off")
ax = plt.subplot(3, 4, 2 * i + 2)
resized_image = learnable_resizer(image[None, ...])
plt.title("Resized Image")
plt.imshow(resized_image.numpy().squeeze())
plt.axis("off")
Corrupt JPEG data: 65 extraneous bytes before marker 0xd9
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

模型构建工具
def get_model():
backbone = keras.applications.DenseNet121(
weights=None,
include_top=True,
classes=2,
input_shape=((TARGET_SIZE[0], TARGET_SIZE[1], 3)),
)
backbone.trainable = True
inputs = layers.Input((INP_SIZE[0], INP_SIZE[1], 3))
x = layers.Rescaling(scale=1.0 / 255)(inputs)
x = learnable_resizer(x)
outputs = backbone(x)
return keras.Model(inputs, outputs)
可学习图像调整大小模块的结构允许与不同的视觉模型灵活集成。
使用可学习调整大小器编译和训练我们的模型
model = get_model()
model.compile(
loss=keras.losses.CategoricalCrossentropy(label_smoothing=0.1),
optimizer="sgd",
metrics=["accuracy"],
)
model.fit(train_ds, validation_data=validation_ds, epochs=EPOCHS)
Epoch 1/5
146/146 ━━━━━━━━━━━━━━━━━━━━ 1790s 12s/step - accuracy: 0.5783 - loss: 0.6877 - val_accuracy: 0.4953 - val_loss: 0.7173
Epoch 2/5
146/146 ━━━━━━━━━━━━━━━━━━━━ 1738s 12s/step - accuracy: 0.6516 - loss: 0.6436 - val_accuracy: 0.6148 - val_loss: 0.6605
Epoch 3/5
146/146 ━━━━━━━━━━━━━━━━━━━━ 1730s 12s/step - accuracy: 0.6881 - loss: 0.6185 - val_accuracy: 0.5529 - val_loss: 0.8655
Epoch 4/5
146/146 ━━━━━━━━━━━━━━━━━━━━ 1725s 12s/step - accuracy: 0.6985 - loss: 0.5980 - val_accuracy: 0.6862 - val_loss: 0.6070
Epoch 5/5
146/146 ━━━━━━━━━━━━━━━━━━━━ 1722s 12s/step - accuracy: 0.7499 - loss: 0.5595 - val_accuracy: 0.6737 - val_loss: 0.6321
<keras.src.callbacks.history.History at 0x7f126c5440a0>
可视化训练后的视觉调整器的输出
plt.figure(figsize=(16, 10))
for i, image in enumerate(sample_images[:6]):
image = image / 255
ax = plt.subplot(3, 4, 2 * i + 1)
plt.title("Input Image")
plt.imshow(image.numpy().squeeze())
plt.axis("off")
ax = plt.subplot(3, 4, 2 * i + 2)
resized_image = learnable_resizer(image[None, ...])
plt.title("Resized Image")
plt.imshow(resized_image.numpy().squeeze() / 10)
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
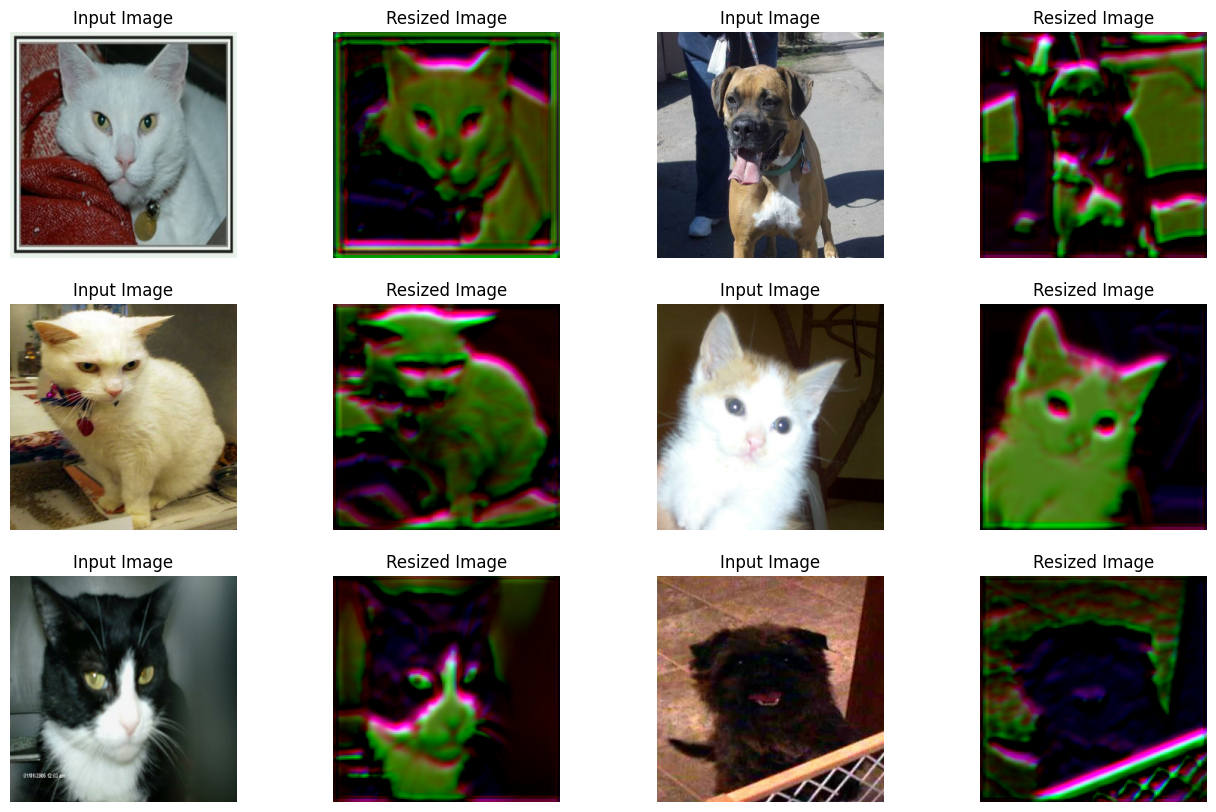
这张图表显示,图像的视觉效果随着训练的进行得到了改善。下表显示了与使用双线性插值相比,使用调整大小模块的好处。
| 模型 | 参数数量(百万) | Top-1 准确率 |
|---|---|---|
| 使用可学习调整大小器 | 7.051717 | 67.67% |
| 未使用可学习调整大小器 | 7.039554 | 60.19% |
有关更多详细信息,您可以查看 此存储库。请注意,上述报告的模型与此示例不同,是在猫狗数据集的 90% 训练集上训练了 10 个 epoch。此外,请注意,由于调整大小模块导致的参数数量增加非常微不足道。为了确保性能的提高不是由于随机性,模型使用了相同的初始随机权重进行训练。
现在,一个值得问的问题是——准确率的提高仅仅是因为与基线相比,模型中增加了更多层(毕竟调整大小器是一个小型网络)吗?
为了证明事实并非如此,作者进行了以下实验:
- 选择一个预训练模型,例如在 (224 x 224) 大小下训练的。
- 然后,首先使用它对调整到较低分辨率的图像进行预测。记录性能。
- 对于第二个实验,在预训练模型顶部插入调整大小模块并进行预热训练。记录性能。
现在,作者认为第二个选项更好,因为它有助于模型学习如何根据给定分辨率更好地调整表征。由于结果纯粹是经验性的,进行一些额外的实验,如分析跨通道交互,可能会更好。值得注意的是,像 Squeeze and Excitation (SE) blocks、Global Context (GC) blocks 这样的元素也会为现有网络增加少量参数,但它们已知有助于网络以系统的方式处理信息,从而提高整体性能。
注意事项
- 为了在视觉模型中强制执行形状偏差,Geirhos 等人使用自然图像和风格化图像的组合来训练它们。研究这种可学习的调整大小模块是否能达到类似的效果可能会很有趣,因为输出似乎会丢弃纹理信息。
- 调整大小模块可以处理任意分辨率和宽高比,这对于对象检测和分割等任务非常重要。
- 还有一个密切相关的主题是自适应图像调整大小,它试图在训练期间自适应地调整图像/特征图的大小。EfficientV2 就使用了这个想法。