使用前向-前向算法进行图像分类
作者: Suvaditya Mukherjee
创建日期 2023/01/08
最后修改日期 2024/09/17
描述: 使用前向-前向算法训练一个密集层模型。

简介
以下示例探讨了如何使用前向-前向算法(Forward-Forward Algorithm)进行训练,而不是 Hinton 在 《前向-前向算法:初步研究》(2022)中提出的传统反向传播方法。
该概念的灵感来源于对 玻尔兹曼机 的理解。反向传播通过成本函数计算实际输出与预测输出之间的差异来调整网络权重。另一方面,FF 算法提出了一种类比:神经元在看到图像及其正确标签的特定组合时会被“激发”。
这种方法受到了皮层中发生的生物学习过程的启发。该方法的一个显著优点是无需再进行网络的反向传播,并且权重更新是局部的,只在层内进行。
由于这仍然是一种实验性的方法,它不能产生最先进的结果。但通过适当的调优,有望接近同等水平。通过这个例子,我们将考察一种允许我们在层内实现前向-前向算法的过程,而不是传统上依赖全局损失函数和优化器的做法。
本教程的结构如下:
- 执行必要的导入
- 加载 MNIST 数据集
- 可视化 MNIST 数据集的随机样本
- 定义一个
FFDense层,重写call方法并实现一个自定义的forwardforward方法来执行权重更新。 - 定义一个
FFNetwork层,重写train_step和predict方法,并实现 2 个自定义函数用于逐样本预测和叠加标签。 - 将 MNIST 从
NumPy数组转换为tf.data.Dataset - 拟合网络
- 可视化结果
- 对测试样本进行推理
由于此示例需要自定义 keras.layers.Layer 和 keras.models.Model 的某些核心函数,请参阅以下资源以了解如何进行自定义:
设置导入
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import tensorflow as tf
import keras
from keras import ops
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
import random
from tensorflow.compiler.tf2xla.python import xla
加载数据集并可视化数据
我们使用 keras.datasets.mnist.load_data() 工具直接以 NumPy 数组的形式获取 MNIST 数据集。然后,我们将其组织成训练集和测试集的格式。
加载数据集后,我们从训练集中选择 4 个随机样本,并使用 matplotlib.pyplot 将它们可视化。
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
print("4 Random Training samples and labels")
idx1, idx2, idx3, idx4 = random.sample(range(0, x_train.shape[0]), 4)
img1 = (x_train[idx1], y_train[idx1])
img2 = (x_train[idx2], y_train[idx2])
img3 = (x_train[idx3], y_train[idx3])
img4 = (x_train[idx4], y_train[idx4])
imgs = [img1, img2, img3, img4]
plt.figure(figsize=(10, 10))
for idx, item in enumerate(imgs):
image, label = item[0], item[1]
plt.subplot(2, 2, idx + 1)
plt.imshow(image, cmap="gray")
plt.title(f"Label : {label}")
plt.show()
4 Random Training samples and labels
定义 FFDense 自定义层
在此自定义层中,我们有一个基础的 keras.layers.Dense 对象,它充当内部的基础 Dense 层。由于权重更新将在层内部进行,因此我们添加了一个由用户接受的 keras.optimizers.Optimizer 对象。在这里,我们使用 Adam 作为优化器,学习率较高,为 0.03。
根据算法的细节,我们必须设置一个 threshold 参数,该参数将用于在每次预测中做出正负决策。默认值为 2.0。由于每个 epoch 都局限于层本身,因此我们还设置了一个 num_epochs 参数(默认为 50)。
我们重写了 call 方法,以便对整个输入空间进行归一化,然后将其通过基础 Dense 层运行,就像在普通的 Dense 层调用中一样。
我们实现了前向-前向算法,它接受两种输入张量,分别代表正样本和负样本。我们在这里编写了一个自定义训练循环,使用 tf.GradientTape()。在这个循环中,我们通过计算预测值与阈值之间的距离来计算每个样本的损失,以了解误差,然后取其平均值得到一个 mean_loss 指标。
借助 tf.GradientTape(),我们计算可训练的基础 Dense 层的梯度更新,并使用该层的局部优化器应用它们。
最后,我们将 call 的结果作为正样本和负样本的 Dense 结果返回,同时还返回最后一个 mean_loss 指标以及在某个全 epoch 运行中的所有损失值。
class FFDense(keras.layers.Layer):
"""
A custom ForwardForward-enabled Dense layer. It has an implementation of the
Forward-Forward network internally for use.
This layer must be used in conjunction with the `FFNetwork` model.
"""
def __init__(
self,
units,
init_optimizer,
loss_metric,
num_epochs=50,
use_bias=True,
kernel_initializer="glorot_uniform",
bias_initializer="zeros",
kernel_regularizer=None,
bias_regularizer=None,
**kwargs,
):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=units,
use_bias=use_bias,
kernel_initializer=kernel_initializer,
bias_initializer=bias_initializer,
kernel_regularizer=kernel_regularizer,
bias_regularizer=bias_regularizer,
)
self.relu = keras.layers.ReLU()
self.optimizer = init_optimizer()
self.loss_metric = loss_metric
self.threshold = 1.5
self.num_epochs = num_epochs
# We perform a normalization step before we run the input through the Dense
# layer.
def call(self, x):
x_norm = ops.norm(x, ord=2, axis=1, keepdims=True)
x_norm = x_norm + 1e-4
x_dir = x / x_norm
res = self.dense(x_dir)
return self.relu(res)
# The Forward-Forward algorithm is below. We first perform the Dense-layer
# operation and then get a Mean Square value for all positive and negative
# samples respectively.
# The custom loss function finds the distance between the Mean-squared
# result and the threshold value we set (a hyperparameter) that will define
# whether the prediction is positive or negative in nature. Once the loss is
# calculated, we get a mean across the entire batch combined and perform a
# gradient calculation and optimization step. This does not technically
# qualify as backpropagation since there is no gradient being
# sent to any previous layer and is completely local in nature.
def forward_forward(self, x_pos, x_neg):
for i in range(self.num_epochs):
with tf.GradientTape() as tape:
g_pos = ops.mean(ops.power(self.call(x_pos), 2), 1)
g_neg = ops.mean(ops.power(self.call(x_neg), 2), 1)
loss = ops.log(
1
+ ops.exp(
ops.concatenate(
[-g_pos + self.threshold, g_neg - self.threshold], 0
)
)
)
mean_loss = ops.cast(ops.mean(loss), dtype="float32")
self.loss_metric.update_state([mean_loss])
gradients = tape.gradient(mean_loss, self.dense.trainable_weights)
self.optimizer.apply_gradients(zip(gradients, self.dense.trainable_weights))
return (
ops.stop_gradient(self.call(x_pos)),
ops.stop_gradient(self.call(x_neg)),
self.loss_metric.result(),
)
定义 FFNetwork 自定义模型
定义了自定义层后,我们还需要重写 train_step 方法,并定义一个与我们的 FFDense 层配合使用的自定义 keras.models.Model。
对于此算法,我们必须将标签“嵌入”到原始图像中。为此,我们利用了 MNIST 图像的结构,其中左上角的 10 个像素始终为零。我们将这部分作为标签空间,以便在图像本身中以视觉方式进行 one-hot 编码。此操作由 overlay_y_on_x 函数执行。
我们将预测函数分解为一个逐样本预测函数,然后由重写的 predict() 函数在整个测试集上调用。这里的预测是通过测量每个图像的每层神经元的“兴奋度”来完成的。然后将这些兴奋度在所有层上求和,以计算一个网络范围的“好度分数”。具有最高“好度分数”的标签被选为样本预测。
重写了 train_step 函数,使其充当根据每层 epoch 数运行各层训练的主要控制循环。
class FFNetwork(keras.Model):
"""
A [`keras.Model`](/api/models/model#model-class) that supports a `FFDense` network creation. This model
can work for any kind of classification task. It has an internal
implementation with some details specific to the MNIST dataset which can be
changed as per the use-case.
"""
# Since each layer runs gradient-calculation and optimization locally, each
# layer has its own optimizer that we pass. As a standard choice, we pass
# the `Adam` optimizer with a default learning rate of 0.03 as that was
# found to be the best rate after experimentation.
# Loss is tracked using `loss_var` and `loss_count` variables.
def __init__(
self,
dims,
init_layer_optimizer=lambda: keras.optimizers.Adam(learning_rate=0.03),
**kwargs,
):
super().__init__(**kwargs)
self.init_layer_optimizer = init_layer_optimizer
self.loss_var = keras.Variable(0.0, trainable=False, dtype="float32")
self.loss_count = keras.Variable(0.0, trainable=False, dtype="float32")
self.layer_list = [keras.Input(shape=(dims[0],))]
self.metrics_built = False
for d in range(len(dims) - 1):
self.layer_list += [
FFDense(
dims[d + 1],
init_optimizer=self.init_layer_optimizer,
loss_metric=keras.metrics.Mean(),
)
]
# This function makes a dynamic change to the image wherein the labels are
# put on top of the original image (for this example, as MNIST has 10
# unique labels, we take the top-left corner's first 10 pixels). This
# function returns the original data tensor with the first 10 pixels being
# a pixel-based one-hot representation of the labels.
@tf.function(reduce_retracing=True)
def overlay_y_on_x(self, data):
X_sample, y_sample = data
max_sample = ops.amax(X_sample, axis=0, keepdims=True)
max_sample = ops.cast(max_sample, dtype="float64")
X_zeros = ops.zeros([10], dtype="float64")
X_update = xla.dynamic_update_slice(X_zeros, max_sample, [y_sample])
X_sample = xla.dynamic_update_slice(X_sample, X_update, [0])
return X_sample, y_sample
# A custom `predict_one_sample` performs predictions by passing the images
# through the network, measures the results produced by each layer (i.e.
# how high/low the output values are with respect to the set threshold for
# each label) and then simply finding the label with the highest values.
# In such a case, the images are tested for their 'goodness' with all
# labels.
@tf.function(reduce_retracing=True)
def predict_one_sample(self, x):
goodness_per_label = []
x = ops.reshape(x, [ops.shape(x)[0] * ops.shape(x)[1]])
for label in range(10):
h, label = self.overlay_y_on_x(data=(x, label))
h = ops.reshape(h, [-1, ops.shape(h)[0]])
goodness = []
for layer_idx in range(1, len(self.layer_list)):
layer = self.layer_list[layer_idx]
h = layer(h)
goodness += [ops.mean(ops.power(h, 2), 1)]
goodness_per_label += [ops.expand_dims(ops.sum(goodness, keepdims=True), 1)]
goodness_per_label = tf.concat(goodness_per_label, 1)
return ops.cast(ops.argmax(goodness_per_label, 1), dtype="float64")
def predict(self, data):
x = data
preds = list()
preds = ops.vectorized_map(self.predict_one_sample, x)
return np.asarray(preds, dtype=int)
# This custom `train_step` function overrides the internal `train_step`
# implementation. We take all the input image tensors, flatten them and
# subsequently produce positive and negative samples on the images.
# A positive sample is an image that has the right label encoded on it with
# the `overlay_y_on_x` function. A negative sample is an image that has an
# erroneous label present on it.
# With the samples ready, we pass them through each `FFLayer` and perform
# the Forward-Forward computation on it. The returned loss is the final
# loss value over all the layers.
@tf.function(jit_compile=False)
def train_step(self, data):
x, y = data
if not self.metrics_built:
# build metrics to ensure they can be queried without erroring out.
# We can't update the metrics' state, as we would usually do, since
# we do not perform predictions within the train step
for metric in self.metrics:
if hasattr(metric, "build"):
metric.build(y, y)
self.metrics_built = True
# Flatten op
x = ops.reshape(x, [-1, ops.shape(x)[1] * ops.shape(x)[2]])
x_pos, y = ops.vectorized_map(self.overlay_y_on_x, (x, y))
random_y = tf.random.shuffle(y)
x_neg, y = tf.map_fn(self.overlay_y_on_x, (x, random_y))
h_pos, h_neg = x_pos, x_neg
for idx, layer in enumerate(self.layers):
if isinstance(layer, FFDense):
print(f"Training layer {idx+1} now : ")
h_pos, h_neg, loss = layer.forward_forward(h_pos, h_neg)
self.loss_var.assign_add(loss)
self.loss_count.assign_add(1.0)
else:
print(f"Passing layer {idx+1} now : ")
x = layer(x)
mean_res = ops.divide(self.loss_var, self.loss_count)
return {"FinalLoss": mean_res}
将 MNIST NumPy 数组转换为 tf.data.Dataset
现在,我们对 NumPy 数组进行一些初步处理,然后将其转换为 tf.data.Dataset 格式,以实现优化加载。
x_train = x_train.astype(float) / 255
x_test = x_test.astype(float) / 255
y_train = y_train.astype(int)
y_test = y_test.astype(int)
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.batch(60000)
test_dataset = test_dataset.batch(10000)
拟合网络并可视化结果
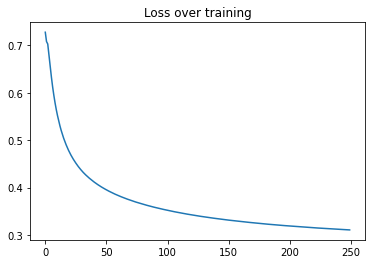
完成所有先前的设置后,我们将运行 model.fit() 并进行 250 个模型 epoch,这将对每个层运行 50*250 个 epoch。我们可以看到每个层在训练时绘制的损失曲线。
model = FFNetwork(dims=[784, 500, 500])
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=0.03),
loss="mse",
jit_compile=False,
metrics=[],
)
epochs = 250
history = model.fit(train_dataset, epochs=epochs)
Epoch 1/250
Training layer 1 now :
Training layer 2 now :
Training layer 1 now :
Training layer 2 now :
1/1 ━━━━━━━━━━━━━━━━━━━━ 90s 90s/step - FinalLoss: 0.7247
Epoch 2/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.7089
Epoch 3/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.6978
Epoch 4/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.6827
Epoch 5/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.6644
Epoch 6/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.6462
Epoch 7/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.6290
Epoch 8/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.6131
Epoch 9/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5986
Epoch 10/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5853
Epoch 11/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5731
Epoch 12/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5621
Epoch 13/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5519
Epoch 14/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5425
Epoch 15/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5338
Epoch 16/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5259
Epoch 17/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5186
Epoch 18/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5117
Epoch 19/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.5052
Epoch 20/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4992
Epoch 21/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4935
Epoch 22/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4883
Epoch 23/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4833
Epoch 24/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4786
Epoch 25/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4741
Epoch 26/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4698
Epoch 27/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4658
Epoch 28/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4620
Epoch 29/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4584
Epoch 30/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4550
Epoch 31/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4517
Epoch 32/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4486
Epoch 33/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4456
Epoch 34/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4429
Epoch 35/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4401
Epoch 36/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4375
Epoch 37/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4350
Epoch 38/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4325
Epoch 39/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4302
Epoch 40/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4279
Epoch 41/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4258
Epoch 42/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4236
Epoch 43/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4216
Epoch 44/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4197
Epoch 45/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4177
Epoch 46/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4159
Epoch 47/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4141
Epoch 48/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4124
Epoch 49/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4107
Epoch 50/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4090
Epoch 51/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4074
Epoch 52/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4059
Epoch 53/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4044
Epoch 54/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.4030
Epoch 55/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4016
Epoch 56/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.4002
Epoch 57/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3988
Epoch 58/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3975
Epoch 59/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3962
Epoch 60/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3950
Epoch 61/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3938
Epoch 62/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3926
Epoch 63/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3914
Epoch 64/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3903
Epoch 65/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3891
Epoch 66/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3880
Epoch 67/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3869
Epoch 68/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3859
Epoch 69/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3849
Epoch 70/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3839
Epoch 71/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3829
Epoch 72/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3819
Epoch 73/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3810
Epoch 74/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3801
Epoch 75/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3792
Epoch 76/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3783
Epoch 77/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3774
Epoch 78/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3765
Epoch 79/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3757
Epoch 80/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3748
Epoch 81/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3740
Epoch 82/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3732
Epoch 83/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3723
Epoch 84/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3715
Epoch 85/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3708
Epoch 86/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3700
Epoch 87/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3692
Epoch 88/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3685
Epoch 89/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3677
Epoch 90/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3670
Epoch 91/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3663
Epoch 92/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3656
Epoch 93/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3649
Epoch 94/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3642
Epoch 95/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3635
Epoch 96/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3629
Epoch 97/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3622
Epoch 98/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3616
Epoch 99/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3610
Epoch 100/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3603
Epoch 101/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3597
Epoch 102/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3591
Epoch 103/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3585
Epoch 104/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3579
Epoch 105/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3573
Epoch 106/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3567
Epoch 107/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3562
Epoch 108/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3556
Epoch 109/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3550
Epoch 110/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3545
Epoch 111/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3539
Epoch 112/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3534
Epoch 113/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3529
Epoch 114/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3524
Epoch 115/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3519
Epoch 116/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3513
Epoch 117/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3508
Epoch 118/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3503
Epoch 119/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3498
Epoch 120/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3493
Epoch 121/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3488
Epoch 122/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3484
Epoch 123/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3479
Epoch 124/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3474
Epoch 125/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3470
Epoch 126/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3465
Epoch 127/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3461
Epoch 128/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3456
Epoch 129/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3452
Epoch 130/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3447
Epoch 131/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3443
Epoch 132/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3439
Epoch 133/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3435
Epoch 134/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3430
Epoch 135/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3426
Epoch 136/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3422
Epoch 137/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3418
Epoch 138/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3414
Epoch 139/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3411
Epoch 140/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3407
Epoch 141/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3403
Epoch 142/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3399
Epoch 143/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3395
Epoch 144/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3391
Epoch 145/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3387
Epoch 146/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3384
Epoch 147/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3380
Epoch 148/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3376
Epoch 149/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3373
Epoch 150/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3369
Epoch 151/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3366
Epoch 152/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3362
Epoch 153/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3359
Epoch 154/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3355
Epoch 155/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3352
Epoch 156/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3349
Epoch 157/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3346
Epoch 158/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3342
Epoch 159/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3339
Epoch 160/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3336
Epoch 161/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3333
Epoch 162/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3330
Epoch 163/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3327
Epoch 164/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3324
Epoch 165/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3321
Epoch 166/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3318
Epoch 167/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3315
Epoch 168/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3312
Epoch 169/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3309
Epoch 170/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3306
Epoch 171/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3303
Epoch 172/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3301
Epoch 173/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3298
Epoch 174/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3295
Epoch 175/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3292
Epoch 176/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3289
Epoch 177/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3287
Epoch 178/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3284
Epoch 179/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3281
Epoch 180/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3279
Epoch 181/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3276
Epoch 182/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3273
Epoch 183/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3271
Epoch 184/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3268
Epoch 185/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3266
Epoch 186/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3263
Epoch 187/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3261
Epoch 188/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3259
Epoch 189/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3256
Epoch 190/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3254
Epoch 191/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3251
Epoch 192/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3249
Epoch 193/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3247
Epoch 194/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3244
Epoch 195/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3242
Epoch 196/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3240
Epoch 197/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3238
Epoch 198/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3235
Epoch 199/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3233
Epoch 200/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3231
Epoch 201/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3228
Epoch 202/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3226
Epoch 203/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3224
Epoch 204/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3222
Epoch 205/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3220
Epoch 206/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3217
Epoch 207/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3215
Epoch 208/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3213
Epoch 209/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3211
Epoch 210/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3209
Epoch 211/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3207
Epoch 212/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3205
Epoch 213/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3203
Epoch 214/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3201
Epoch 215/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3199
Epoch 216/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3197
Epoch 217/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3195
Epoch 218/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3193
Epoch 219/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3191
Epoch 220/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3190
Epoch 221/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3188
Epoch 222/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3186
Epoch 223/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3184
Epoch 224/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3182
Epoch 225/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3180
Epoch 226/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3179
Epoch 227/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3177
Epoch 228/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3175
Epoch 229/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3173
Epoch 230/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3171
Epoch 231/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3170
Epoch 232/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3168
Epoch 233/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3166
Epoch 234/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3164
Epoch 235/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3163
Epoch 236/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3161
Epoch 237/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3159
Epoch 238/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3158
Epoch 239/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3156
Epoch 240/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 41s 41s/step - FinalLoss: 0.3154
Epoch 241/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3152
Epoch 242/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3151
Epoch 243/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3149
Epoch 244/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3148
Epoch 245/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3146
Epoch 246/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3145
Epoch 247/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3143
Epoch 248/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3141
Epoch 249/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3140
Epoch 250/250
1/1 ━━━━━━━━━━━━━━━━━━━━ 40s 40s/step - FinalLoss: 0.3138
进行推理和测试
在对模型进行了大量训练后,我们现在考察它在测试集上的表现。我们计算准确率分数来仔细分析结果。
preds = model.predict(ops.convert_to_tensor(x_test))
preds = preds.reshape((preds.shape[0], preds.shape[1]))
results = accuracy_score(preds, y_test)
print(f"Test Accuracy score : {results*100}%")
plt.plot(range(len(history.history["FinalLoss"])), history.history["FinalLoss"])
plt.title("Loss over training")
plt.show()
Test Accuracy score : 97.56%
结论
本示例通过 TensorFlow 和 Keras 包演示了前向-前向算法的工作原理。尽管 Hinton 教授在其论文中呈现的实验结果目前仅限于 MNIST 和 Fashion-MNIST 等较小的模型和数据集,但预计未来的论文会发布关于 LLMs 等更大模型的后续结果。
在论文中,Hinton 教授报告了一个 2000 个单元、4 个隐藏层、全连接网络的测试准确率误差为 1.36%,运行 60 个 epoch(并提到反向传播仅需 20 个 epoch 即可达到类似性能)。另一项将学习率加倍并训练 40 个 epoch 的运行,得到了稍差的 1.46% 的误差率。
当前示例并未产生最先进的结果。但通过对学习率、模型架构(Dense 层中的单元数、核激活、初始化、正则化等)进行适当的调优,可以改进结果以匹配论文的声明。