在 KerasCV 中分割任何东西!
作者:Tirth Patel,Ian Stenbit
创建日期 2023/12/04
最后修改日期 2023/12/19
描述:使用文本、框和点提示在 KerasCV 中分割任何东西。

概述
分割任何东西模型 (SAM) 可以根据点或框等输入提示生成高质量的目标掩码,并且可以用于生成图像中所有目标的掩码。它已在 数据集 上进行了训练,该数据集包含 1100 万张图像和 11 亿个掩码,在各种分割任务中具有强大的零样本性能。
在本指南中,我们将展示如何使用 KerasCV 中对 分割任何东西模型 的实现,并展示 TensorFlow 和 JAX 的性能提升有多强大。
首先,让我们获取我们演示所需的所有依赖项和图像。
!pip install -Uq keras-cv
!pip install -Uq keras
!wget -q https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/truck.jpg
选择你的后端
使用 Keras 3,你可以选择使用你喜欢的后端!
import os
os.environ["KERAS_BACKEND"] = "jax"
import timeit
import numpy as np
import matplotlib.pyplot as plt
import keras
from keras import ops
import keras_cv
辅助函数
让我们定义一些用于可视化图像、提示和分割结果的辅助函数。
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(
pos_points[:, 0],
pos_points[:, 1],
color="green",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
ax.scatter(
neg_points[:, 0],
neg_points[:, 1],
color="red",
marker="*",
s=marker_size,
edgecolor="white",
linewidth=1.25,
)
def show_box(box, ax):
box = box.reshape(-1)
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(
plt.Rectangle((x0, y0), w, h, edgecolor="green", facecolor=(0, 0, 0, 0), lw=2)
)
def inference_resizing(image, pad=True):
# Compute Preprocess Shape
image = ops.cast(image, dtype="float32")
old_h, old_w = image.shape[0], image.shape[1]
scale = 1024 * 1.0 / max(old_h, old_w)
new_h = old_h * scale
new_w = old_w * scale
preprocess_shape = int(new_h + 0.5), int(new_w + 0.5)
# Resize the image
image = ops.image.resize(image[None, ...], preprocess_shape)[0]
# Pad the shorter side
if pad:
pixel_mean = ops.array([123.675, 116.28, 103.53])
pixel_std = ops.array([58.395, 57.12, 57.375])
image = (image - pixel_mean) / pixel_std
h, w = image.shape[0], image.shape[1]
pad_h = 1024 - h
pad_w = 1024 - w
image = ops.pad(image, [(0, pad_h), (0, pad_w), (0, 0)])
# KerasCV now rescales the images and normalizes them.
# Just unnormalize such that when KerasCV normalizes them
# again, the padded values map to 0.
image = image * pixel_std + pixel_mean
return image
获取预训练的 SAM 模型
我们可以使用 KerasCV 的 from_preset 工厂方法初始化训练好的 SAM 模型。在这里,我们使用在 SA-1B 数据集上训练的大型 ViT 主干 (sam_huge_sa1b) 来生成高质量的分割掩码。你也可以使用 sam_large_sa1b 或 sam_base_sa1b 中的一种,以获得更好的性能(以降低分割掩码的质量为代价)。
model = keras_cv.models.SegmentAnythingModel.from_preset("sam_huge_sa1b")
了解提示
分割任何东西允许使用点、框和掩码对图像进行提示
- 点提示是最基本的一种:模型试图根据图像上的一个点来猜测目标。该点可以是前景点(即所需的分割掩码包含该点)或背景点(即该点位于所需的掩码之外)。
- 另一种提示模型的方法是使用框。给定一个边界框,模型试图分割其中包含的目标。
- 最后,模型还可以使用掩码本身进行提示。例如,这对于细化先前预测或已知的分割掩码的边界很有用。
使模型非常强大的地方在于能够组合上述提示。点、框和掩码提示可以以多种不同的方式组合起来,以获得最佳结果。
让我们看看在 KerasCV 中将这些提示传递给分割任何东西模型的语义。SAM 模型的输入是一个字典,其中包含以下键
"images":要分割的一批图像。必须为(B, 1024, 1024, 3)形状。"points":一批点提示。每个点都是一个(x, y)坐标,源自图像的左上角。换句话说,每个点都是(r, c)的形式,其中r和c是图像中像素的行和列。必须为(B, N, 2)形状。"labels":给定点的标签批次。1代表前景点,0代表背景点。必须为(B, N)形状。"boxes":一批框。请注意,模型每个批次只接受一个框。因此,期望的形状为(B, 1, 2, 2)。每个框都是 2 个点的集合:框的左上角和右下角。这里的点遵循与点提示相同的语义。这里的第二个维度中的1代表框提示的存在。如果缺少框提示,则必须传递形状为(B, 0, 2, 2)的占位符输入。"masks":一批掩码。与框提示一样,每个图像只允许一个掩码提示。如果存在掩码提示,则输入掩码的形状必须为(B, 1, 256, 256, 1),如果缺少掩码提示,则形状必须为(B, 0, 256, 256, 1)。
占位符提示仅在直接调用模型时需要(即 model(...))。当调用 predict 方法时,可以省略输入字典中的缺失提示。
点提示
首先,让我们使用点提示分割一个图像。我们加载图像并将其调整为 (1024, 1024) 形状,这是预训练的 SAM 模型期望的图像大小。
# Load our image
image = np.array(keras.utils.load_img("truck.jpg"))
image = inference_resizing(image)
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
plt.axis("on")
plt.show()

接下来,我们将定义我们要分割的目标上的点。让我们尝试分割卡车车窗玻璃窗格,其坐标为 (284, 213)。
# Define the input point prompt
input_point = np.array([[284, 213.5]])
input_label = np.array([1])
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
show_points(input_point, input_label, plt.gca())
plt.axis("on")
plt.show()

现在让我们调用模型的 predict 方法以获取分割掩码。
注意:我们不直接调用模型 (model(...)),因为需要占位符提示才能这样做。缺失提示由 predict 方法自动处理,因此我们改为调用它。此外,当没有框提示时,需要使用零点提示和 -1 标签提示分别填充点和标签。下面的单元格演示了它是如何工作的。
outputs = model.predict(
{
"images": image[np.newaxis, ...],
"points": np.concatenate(
[input_point[np.newaxis, ...], np.zeros((1, 1, 2))], axis=1
),
"labels": np.concatenate(
[input_label[np.newaxis, ...], np.full((1, 1), fill_value=-1)], axis=1
),
}
)
1/1 ━━━━━━━━━━━━━━━━━━━━ 48s 48s/step
SegmentAnythingModel.predict 返回两个输出。第一个是形状为 (1, 4, 256, 256) 的 logits(分割掩码),另一个是每个预测掩码的 IoU 置信度分数(形状为 (1, 4))。预训练的 SAM 模型预测四个掩码:第一个是模型针对给定提示所能找到的最佳掩码,另外三个是备用掩码,可以在最佳预测不包含所需目标的情况下使用。用户可以选择他们喜欢的任何掩码。
让我们可视化模型返回的掩码!
# Resize the mask to our image shape i.e. (1024, 1024)
mask = inference_resizing(outputs["masks"][0][0][..., None], pad=False)[..., 0]
# Convert the logits to a numpy array
# and convert the logits to a boolean mask
mask = ops.convert_to_numpy(mask) > 0.0
iou_score = ops.convert_to_numpy(outputs["iou_pred"][0][0])
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"IoU Score: {iou_score:.3f}", fontsize=18)
plt.axis("off")
plt.show()

正如预期的那样,模型返回了卡车车窗玻璃窗格的分割掩码。但是,我们的点提示也可以意味着其他一系列东西。例如,另一个包含我们点的可能掩码只是窗格的右侧或整辆卡车。
让我们也可视化模型预测的其他掩码。
fig, ax = plt.subplots(1, 3, figsize=(20, 60))
masks, scores = outputs["masks"][0][1:], outputs["iou_pred"][0][1:]
for i, (mask, score) in enumerate(zip(masks, scores)):
mask = inference_resizing(mask[..., None], pad=False)[..., 0]
mask, score = map(ops.convert_to_numpy, (mask, score))
mask = 1 * (mask > 0.0)
ax[i].imshow(ops.convert_to_numpy(image) / 255.0)
show_mask(mask, ax[i])
show_points(input_point, input_label, ax[i])
ax[i].set_title(f"Mask {i+1}, Score: {score:.3f}", fontsize=12)
ax[i].axis("off")
plt.show()

不错!SAM 能够捕捉到我们点提示的歧义性,并返回了其他可能的分割掩码。
框提示
现在,让我们看看如何使用框提示模型。该框使用两个点来指定,即边界框的左上角和右下角,格式为 xyxy。让我们使用围绕卡车左前轮胎的边界框来提示模型。
# Let's specify the box
input_box = np.array([[240, 340], [400, 500]])
outputs = model.predict(
{"images": image[np.newaxis, ...], "boxes": input_box[np.newaxis, np.newaxis, ...]}
)
mask = inference_resizing(outputs["masks"][0][0][..., None], pad=False)[..., 0]
mask = ops.convert_to_numpy(mask) > 0.0
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
show_mask(mask, plt.gca())
show_box(input_box, plt.gca())
plt.axis("off")
plt.show()
1/1 ━━━━━━━━━━━━━━━━━━━━ 13s 13s/step

太棒了!模型完美地分割了我们边界框中的左前轮胎。
组合提示
为了充分发挥模型的潜力,让我们组合框和点提示,看看模型会做什么。
# Let's specify the box
input_box = np.array([[240, 340], [400, 500]])
# Let's specify the point and mark it background
input_point = np.array([[325, 425]])
input_label = np.array([0])
outputs = model.predict(
{
"images": image[np.newaxis, ...],
"points": input_point[np.newaxis, ...],
"labels": input_label[np.newaxis, ...],
"boxes": input_box[np.newaxis, np.newaxis, ...],
}
)
mask = inference_resizing(outputs["masks"][0][0][..., None], pad=False)[..., 0]
mask = ops.convert_to_numpy(mask) > 0.0
plt.figure(figsize=(10, 10))
plt.imshow(ops.convert_to_numpy(image) / 255.0)
show_mask(mask, plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis("off")
plt.show()
1/1 ━━━━━━━━━━━━━━━━━━━━ 16s 16s/step

太棒了!模型理解了我们想要从掩码中排除的目标是轮胎的轮辋。
文本提示
最后,让我们看看如何将文本提示与 KerasCV 的 SegmentAnythingModel 一起使用。
对于此演示,我们将使用 官方 Grounding DINO 模型。Grounding DINO 是一个模型,它将 (图像,文本) 对作为输入,并生成围绕 图像 中由 文本 描述的目标的边界框。你可以参考 论文,以详细了解模型的实现。
对于演示的这一部分,我们需要从源代码安装 groundingdino 包
pip install -U git+https://github.com/IDEA-Research/GroundingDINO.git
然后,我们可以安装预训练模型的权重和配置
!wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
!wget -q https://raw.githubusercontent.com/IDEA-Research/GroundingDINO/v0.1.0-alpha2/groundingdino/config/GroundingDINO_SwinT_OGC.py
from groundingdino.util.inference import Model as GroundingDINO
CONFIG_PATH = "GroundingDINO_SwinT_OGC.py"
WEIGHTS_PATH = "groundingdino_swint_ogc.pth"
grounding_dino = GroundingDINO(CONFIG_PATH, WEIGHTS_PATH)
/home/tirthp/oss/virtualenvs/keras-io-dev/lib/python3.10/site-packages/torch/functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3526.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
final text_encoder_type: bert-base-uncased
让我们为这一部分加载一张狗的图片!
filepath = keras.utils.get_file(
origin="https://storage.googleapis.com/keras-cv/test-images/mountain-dog.jpeg"
)
image = np.array(keras.utils.load_img(filepath))
image = ops.convert_to_numpy(inference_resizing(image))
plt.figure(figsize=(10, 10))
plt.imshow(image / 255.0)
plt.axis("on")
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
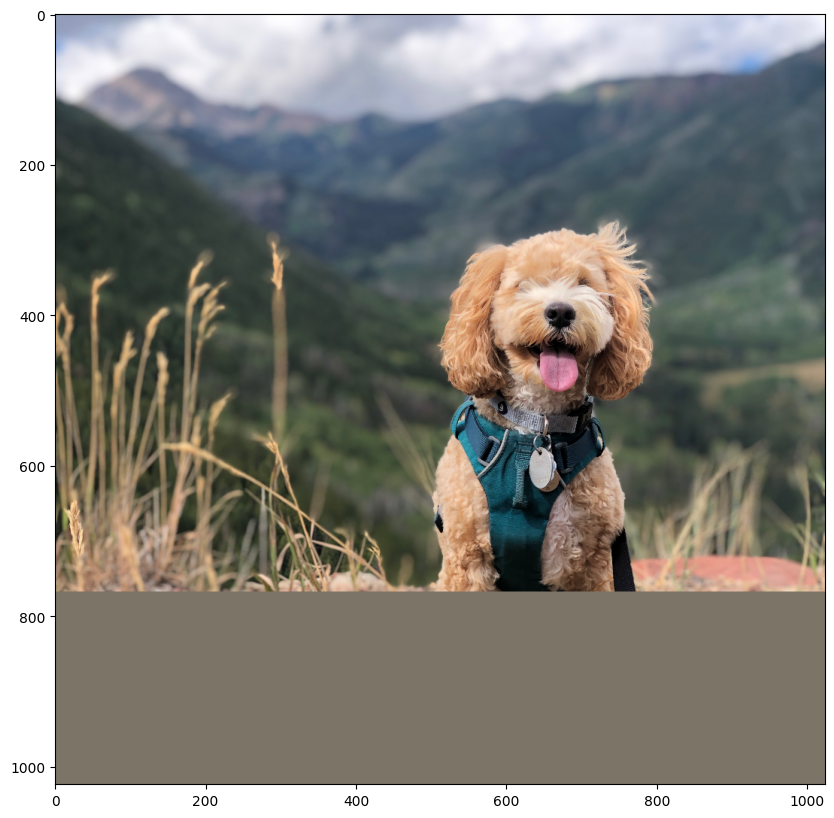
我们首先使用 Grounding DINO 模型预测我们要分割的目标的边界框。然后,我们使用边界框提示 SAM 模型以获取分割掩码。
让我们尝试分割出狗的马具。更改下面的图像和文本,以便使用图像中的文本分割你想要的任何东西!
# Let's predict the bounding box for the harness of the dog
boxes = grounding_dino.predict_with_caption(image.astype(np.uint8), "harness")
boxes = np.array(boxes[0].xyxy)
outputs = model.predict(
{
"images": np.repeat(image[np.newaxis, ...], boxes.shape[0], axis=0),
"boxes": boxes.reshape(-1, 1, 2, 2),
},
batch_size=1,
)
/home/tirthp/oss/virtualenvs/keras-io-dev/lib/python3.10/site-packages/transformers/modeling_utils.py:942: FutureWarning: The `device` argument is deprecated and will be removed in v5 of Transformers.
warnings.warn(
/home/tirthp/oss/virtualenvs/keras-io-dev/lib/python3.10/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
/home/tirthp/oss/virtualenvs/keras-io-dev/lib/python3.10/site-packages/torch/utils/checkpoint.py:61: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
1/1 ━━━━━━━━━━━━━━━━━━━━ 13s 13s/step
就这样!我们使用 Gounding DINO + SAM 的组合,根据我们的文本提示获得了分割掩码!这是一种非常强大的技术,可以将不同的模型组合起来以扩展应用程序!
让我们可视化结果。
plt.figure(figsize=(10, 10))
plt.imshow(image / 255.0)
for mask in outputs["masks"]:
mask = inference_resizing(mask[0][..., None], pad=False)[..., 0]
mask = ops.convert_to_numpy(mask) > 0.0
show_mask(mask, plt.gca())
show_box(boxes, plt.gca())
plt.axis("off")
plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

优化 SAM
你可以使用 mixed_float16 或 bfloat16 数据类型策略来获得巨大的加速和内存优化,而精度损失相对较低。
# Load our image
image = np.array(keras.utils.load_img("truck.jpg"))
image = inference_resizing(image)
# Specify the prompt
input_box = np.array([[240, 340], [400, 500]])
# Let's first see how fast the model is with float32 dtype
time_taken = timeit.repeat(
'model.predict({"images": image[np.newaxis, ...], "boxes": input_box[np.newaxis, np.newaxis, ...]}, verbose=False)',
repeat=3,
number=3,
globals=globals(),
)
print(f"Time taken with float32 dtype: {min(time_taken) / 3:.10f}s")
# Set the dtype policy in Keras
keras.mixed_precision.set_global_policy("mixed_float16")
model = keras_cv.models.SegmentAnythingModel.from_preset("sam_huge_sa1b")
time_taken = timeit.repeat(
'model.predict({"images": image[np.newaxis, ...], "boxes": input_box[np.newaxis, np.newaxis, ...]}, verbose=False)',
repeat=3,
number=3,
globals=globals(),
)
print(f"Time taken with float16 dtype: {min(time_taken) / 3:.10f}s")
Time taken with float32 dtype: 0.5304666963s
Time taken with float16 dtype: 0.1586400040s
以下是 KerasCV 实现与原始 PyTorch 实现的比较!
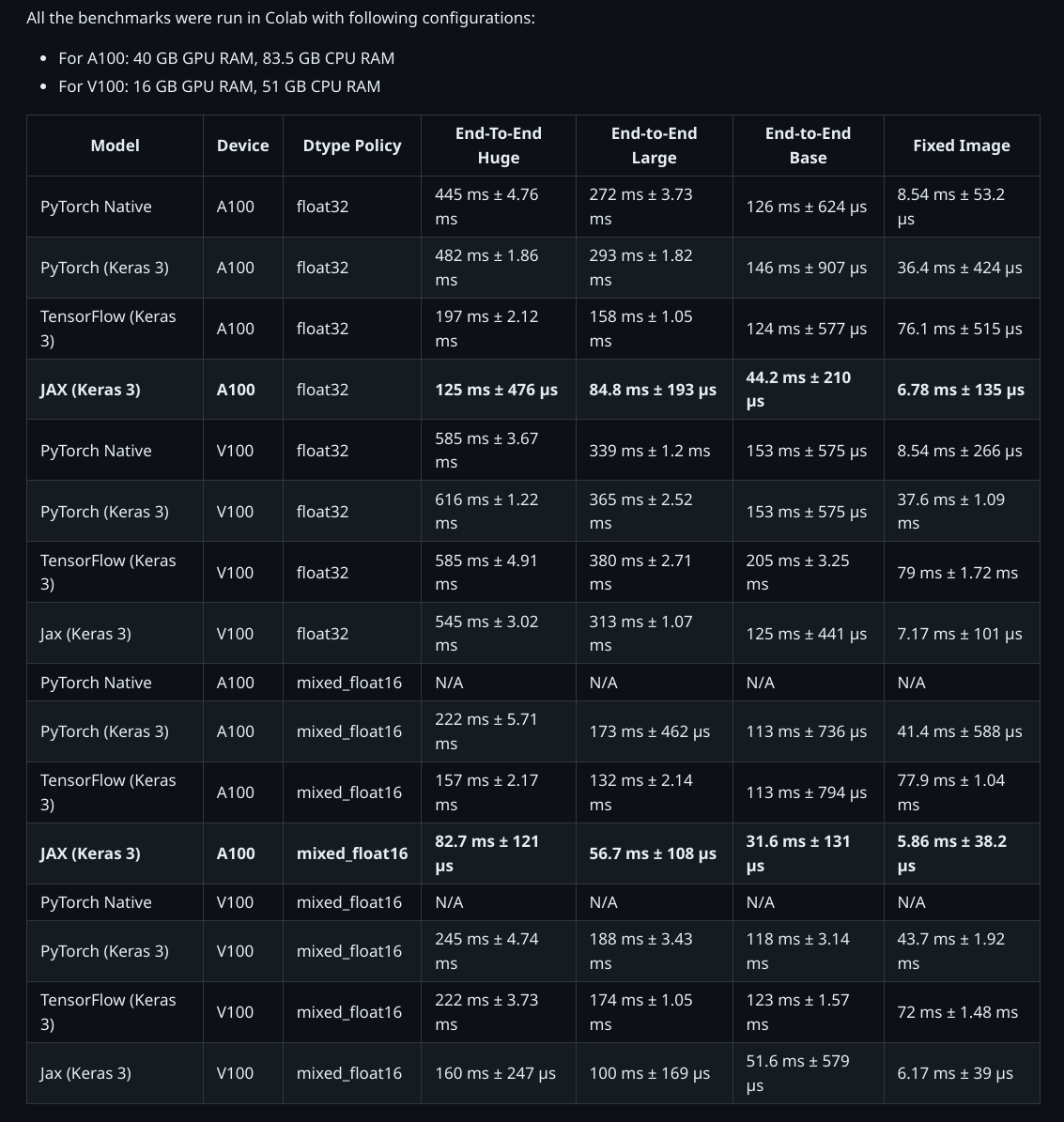
用于生成基准的脚本位于 此处。
结论
KerasCV 的 SegmentAnythingModel 支持各种应用,并且在 Keras 3 的帮助下,可以在 TensorFlow、JAX 和 PyTorch 上运行该模型!在 JAX 和 TensorFlow 中 XLA 的帮助下,该模型的运行速度比原始实现快几倍。此外,使用 Keras 的混合精度支持只需一行代码即可帮助优化内存使用和计算时间!
有关更高级的用法,请查看 自动掩码生成器演示。