使用 KerasCV 进行 CutMix、MixUp 和 RandAugment 图像增强
作者: lukewood
创建日期 2022/04/08
最后修改日期 2022/04/08
描述:使用 KerasCV 通过 CutMix、MixUp、RandAugment 等方法增强图像。

概述
KerasCV 使得为图像分类和目标检测任务组装最先进的行业级数据增强管道变得容易。KerasCV 提供了一套广泛的预处理层,实现了常见的数据增强技术。
也许最实用的三个层是 keras_cv.layers.CutMix、keras_cv.layers.MixUp 和 keras_cv.layers.RandAugment。这些层在几乎所有最先进的图像分类管道中都有使用。
本指南将向您展示如何将这些层组合到您自己的图像分类任务数据增强管道中。本指南还将引导您完成自定义 KerasCV 数据增强管道的过程。
导入和设置
KerasCV 使用 Keras 3 与 TensorFlow、PyTorch 或 Jax 中的任何一个一起工作。在下面的指南中,我们将使用 jax 后端。本指南在 TensorFlow 或 PyTorch 后端运行无需任何更改,只需更新下面的 KERAS_BACKEND 即可。
!pip install -q --upgrade keras-cv
!pip install -q --upgrade keras # Upgrade to Keras 3.
我们首先导入所有必需的包
import os
os.environ["KERAS_BACKEND"] = "jax" # @param ["tensorflow", "jax", "torch"]
import matplotlib.pyplot as plt
# Import tensorflow for [`tf.data`](https://tensorflowcn.cn/api_docs/python/tf/data) and its preprocessing map functions
import tensorflow as tf
import tensorflow_datasets as tfds
import keras
import keras_cv
数据加载
本指南使用 102 类花卉数据集 用于演示目的。
首先,我们加载数据集
BATCH_SIZE = 32
AUTOTUNE = tf.data.AUTOTUNE
tfds.disable_progress_bar()
data, dataset_info = tfds.load("oxford_flowers102", with_info=True, as_supervised=True)
train_steps_per_epoch = dataset_info.splits["train"].num_examples // BATCH_SIZE
val_steps_per_epoch = dataset_info.splits["test"].num_examples // BATCH_SIZE
Downloading and preparing dataset 328.90 MiB (download: 328.90 MiB, generated: 331.34 MiB, total: 660.25 MiB) to /usr/local/google/home/rameshsampath/tensorflow_datasets/oxford_flowers102/2.1.1...
Dataset oxford_flowers102 downloaded and prepared to /usr/local/google/home/rameshsampath/tensorflow_datasets/oxford_flowers102/2.1.1. Subsequent calls will reuse this data.
接下来,我们将图像调整为常数大小 (224, 224) 并对标签进行 one-hot 编码。请注意,keras_cv.layers.CutMix 和 keras_cv.layers.MixUp 要求目标进行 one-hot 编码。这是因为它们以稀疏标签表示形式无法实现的方式修改了目标的值。
IMAGE_SIZE = (224, 224)
num_classes = dataset_info.features["label"].num_classes
def to_dict(image, label):
image = tf.image.resize(image, IMAGE_SIZE)
image = tf.cast(image, tf.float32)
label = tf.one_hot(label, num_classes)
return {"images": image, "labels": label}
def prepare_dataset(dataset, split):
if split == "train":
return (
dataset.shuffle(10 * BATCH_SIZE)
.map(to_dict, num_parallel_calls=AUTOTUNE)
.batch(BATCH_SIZE)
)
if split == "test":
return dataset.map(to_dict, num_parallel_calls=AUTOTUNE).batch(BATCH_SIZE)
def load_dataset(split="train"):
dataset = data[split]
return prepare_dataset(dataset, split)
train_dataset = load_dataset()
让我们检查一下数据集中的几个样本
def visualize_dataset(dataset, title):
plt.figure(figsize=(6, 6)).suptitle(title, fontsize=18)
for i, samples in enumerate(iter(dataset.take(9))):
images = samples["images"]
plt.subplot(3, 3, i + 1)
plt.imshow(images[0].numpy().astype("uint8"))
plt.axis("off")
plt.show()
visualize_dataset(train_dataset, title="Before Augmentation")

太好了!现在我们可以进入增强步骤了。
RandAugment
RandAugment 已被证明可以在众多数据集上提供改进的图像分类结果。它对图像执行一组标准的增强操作。
要在 KerasCV 中使用 RandAugment,您需要提供一些值
value_range描述了图像中涵盖的值范围magnitude是一个介于 0 到 1 之间的数值,描述了所应用扰动的强度augmentations_per_image是一个整数,告诉层对每个单独图像应用多少增强操作- (可选)
magnitude_stddev允许从标准差为magnitude_stddev的分布中随机采样magnitude - (可选)
rate指示在每个层应用增强的概率。
您可以在 RandAugment API 文档 中了解更多关于这些参数的信息。
让我们使用 KerasCV 的 RandAugment 实现。
rand_augment = keras_cv.layers.RandAugment(
value_range=(0, 255),
augmentations_per_image=3,
magnitude=0.3,
magnitude_stddev=0.2,
rate=1.0,
)
def apply_rand_augment(inputs):
inputs["images"] = rand_augment(inputs["images"])
return inputs
train_dataset = load_dataset().map(apply_rand_augment, num_parallel_calls=AUTOTUNE)
最后,让我们检查一些结果
visualize_dataset(train_dataset, title="After RandAugment")

尝试调整 magnitude 设置以查看更多结果。
CutMix 和 MixUp:生成高质量的类间示例
CutMix 和 MixUp 允许我们生成类间示例。CutMix 随机裁剪出某个图像的部分并将其放置在另一个图像上,而 MixUp 对两个图像之间的像素值进行插值。这两种方法都可以防止模型过度拟合训练分布,并提高模型能够泛化到分布外示例的可能性。此外,CutMix 还可以防止您的模型过度依赖任何特定特征来执行分类。您可以在各自的论文中了解更多关于这些技术的信息
在本示例中,我们将独立地在手动创建的预处理管道中使用 CutMix 和 MixUp。在大多数最先进的管道中,图像会随机增强,要么使用 CutMix、MixUp,要么都不使用。下面的函数同时实现了这两者。
cut_mix = keras_cv.layers.CutMix()
mix_up = keras_cv.layers.MixUp()
def cut_mix_and_mix_up(samples):
samples = cut_mix(samples, training=True)
samples = mix_up(samples, training=True)
return samples
train_dataset = load_dataset().map(cut_mix_and_mix_up, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After CutMix and MixUp")

太好了!看来我们已成功地将 CutMix 和 MixUp 添加到了我们的预处理管道中。
自定义增强管道
也许您想要从 RandAugment 中排除某种增强操作,或者您想要将 keras_cv.layers.GridMask 作为默认 RandAugment 增强操作的选项包含在内。
KerasCV 允许您使用 keras_cv.layers.RandomAugmentationPipeline 层构建生产级的自定义数据增强管道。此类的操作类似于 RandAugment;它选择一个随机层来对每个图像应用 augmentations_per_image 次。RandAugment 可以被认为是 RandomAugmentationPipeline 的一个特例。事实上,我们的 RandAugment 实现内部继承了 RandomAugmentationPipeline。
在本示例中,我们将创建一个自定义 RandomAugmentationPipeline,方法是从标准 RandAugment 策略中删除 RandomRotation 层,并用 GridMask 层代替它。
第一步,让我们使用辅助方法 RandAugment.get_standard_policy() 创建一个基本管道。
layers = keras_cv.layers.RandAugment.get_standard_policy(
value_range=(0, 255), magnitude=0.75, magnitude_stddev=0.3
)
首先,让我们筛选掉 RandomRotation 层
layers = [
layer for layer in layers if not isinstance(layer, keras_cv.layers.RandomRotation)
]
接下来,让我们将 keras_cv.layers.GridMask 添加到我们的层中
layers = layers + [keras_cv.layers.GridMask()]
最后,我们可以将管道组合起来
pipeline = keras_cv.layers.RandomAugmentationPipeline(
layers=layers, augmentations_per_image=3
)
def apply_pipeline(inputs):
inputs["images"] = pipeline(inputs["images"])
return inputs
让我们检查一下结果!
train_dataset = load_dataset().map(apply_pipeline, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After custom pipeline")
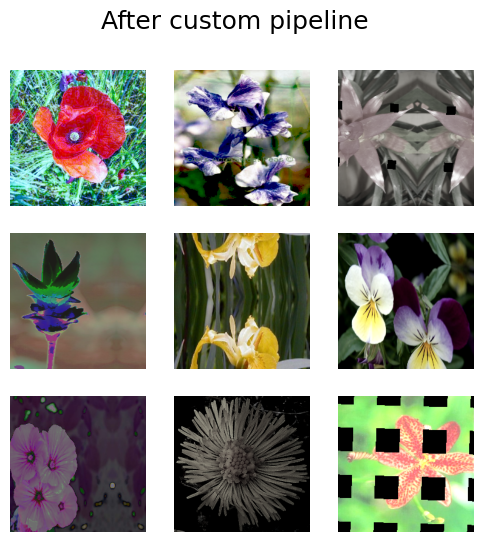
太棒了!如您所见,没有图像被随机旋转。您可以根据需要自定义管道
pipeline = keras_cv.layers.RandomAugmentationPipeline(
layers=[keras_cv.layers.GridMask(), keras_cv.layers.Grayscale(output_channels=3)],
augmentations_per_image=1,
)
此管道将应用 GrayScale 或 GridMask
train_dataset = load_dataset().map(apply_pipeline, num_parallel_calls=AUTOTUNE)
visualize_dataset(train_dataset, title="After custom pipeline")

看起来不错!您可以根据需要使用 RandomAugmentationPipeline。
训练 CNN
作为最后一个练习,让我们尝试使用一些这些层。在本节中,我们将使用 CutMix、MixUp 和 RandAugment 在 Oxford 花卉数据集上训练一个最先进的 ResNet50 图像分类器。
def preprocess_for_model(inputs):
images, labels = inputs["images"], inputs["labels"]
images = tf.cast(images, tf.float32)
return images, labels
train_dataset = (
load_dataset()
.map(apply_rand_augment, num_parallel_calls=AUTOTUNE)
.map(cut_mix_and_mix_up, num_parallel_calls=AUTOTUNE)
)
visualize_dataset(train_dataset, "CutMix, MixUp and RandAugment")
train_dataset = train_dataset.map(preprocess_for_model, num_parallel_calls=AUTOTUNE)
test_dataset = load_dataset(split="test")
test_dataset = test_dataset.map(preprocess_for_model, num_parallel_calls=AUTOTUNE)
train_dataset = train_dataset.prefetch(AUTOTUNE)
test_dataset = test_dataset.prefetch(AUTOTUNE)

接下来,我们应该创建模型本身。请注意,我们在损失函数中使用了 label_smoothing=0.1。使用 MixUp 时,强烈建议使用标签平滑。
input_shape = IMAGE_SIZE + (3,)
def get_model():
model = keras_cv.models.ImageClassifier.from_preset(
"efficientnetv2_s", num_classes=num_classes
)
model.compile(
loss=keras.losses.CategoricalCrossentropy(label_smoothing=0.1),
optimizer=keras.optimizers.SGD(momentum=0.9),
metrics=["accuracy"],
)
return model
最后,我们训练模型
model = get_model()
model.fit(
train_dataset,
epochs=1,
validation_data=test_dataset,
)
32/32 ━━━━━━━━━━━━━━━━━━━━ 103s 2s/step - accuracy: 0.0059 - loss: 4.6941 - val_accuracy: 0.0114 - val_loss: 10.4028
<keras.src.callbacks.history.History at 0x7fd0d00e07c0>
结论和后续步骤
这就是使用 KerasCV 组装最先进的图像增强管道的全部内容!
作为读者的额外练习,您可以
- 对 RandAugment 参数执行超参数搜索以提高分类器精度
- 用您自己的数据集替换 Oxford 花卉数据集
- 尝试使用自定义的
RandomAugmentationPipeline对象。
目前,在 Keras 核心和 KerasCV 之间有 28 个图像增强层!这些层都可以独立使用,也可以在管道中使用。查看它们,如果您发现缺少您需要的增强技术,请在 KerasCV 上提交 GitHub 问题。