KerasHub 入门指南
作者: Matthew Watson, Jonathan Bischof
创建日期 2022/12/15
最后修改日期 2024/10/17
描述: KerasHub API 简介。

KerasHub 是一个旨在简洁、灵活且快速的预训练模型库。该库提供了流行的模型架构的 Keras 3 实现,并配有一系列可在 Kaggle 上找到的预训练检查点。模型可用于 TensorFlow、Jax 和 Torch 后端上的训练和推理。
KerasHub 是核心 Keras API 的扩展;KerasHub 组件被提供为 keras.Layer 和 keras.Model。如果您熟悉 Keras,恭喜!您已经掌握了 KerasHub 的大部分内容。
本指南旨在对整个库进行易于理解的介绍。我们将从使用高级 API 对图像进行分类和生成文本开始,然后逐步展示模型和训练的更深入的定制。在本指南中,我们将使用 Keras 的官方吉祥物 Professor Keras 作为材料复杂度的视觉参考。
一如既往,我们将 Keras 指南专注于实际代码示例。您可以通过点击指南顶部的 Colab 链接,随时在此处尝试代码。
安装与设置
首先,让我们安装 keras-hub。该库可在 PyPI 上找到,因此我们可以直接使用 pip 安装它。
!pip install --upgrade --quiet keras-hub keras
Keras 3 是建立在 TensorFlow、Jax 和 Torch 后端之上的。在编写 Keras 代码时,您应该在任何库导入之前先指定后端。本指南将使用 Jax 后端,但您可以使用 torch 或 tensorflow,而无需更改本指南其余部分的任何一行代码。这就是 Keras 3 的强大之处!
我们还将设置 XLA_PYTHON_CLIENT_MEM_FRACTION,该设置会从一开始就为 Jax 释放整个 GPU 以供使用。
import os
os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"] = "1.0"
最后,我们需要进行一些额外的设置才能访问本指南中使用的模型。许多流行的开源 LLM,例如 Google 的 Gemma 和 Meta 的 Llama,都需要在访问模型权重之前接受社区许可。本指南将使用 Gemma,因此我们可以按照以下步骤操作:
- 访问 Gemma 2 模型页面,并在顶部的横幅处接受许可。
- 通过访问 Kaggle 设置并点击“API”部分下的“创建新令牌”按钮来生成 Kaggle API 密钥。
- 在您的 colab 笔记本中,点击左侧工具栏中的密钥图标。添加两个秘密:
KAGGLE_USERNAME(填写您的用户名)和KAGGLE_KEY(填写您刚刚创建的 API 密钥)。确保这些秘密对您正在运行的笔记本可见。
API 快速入门
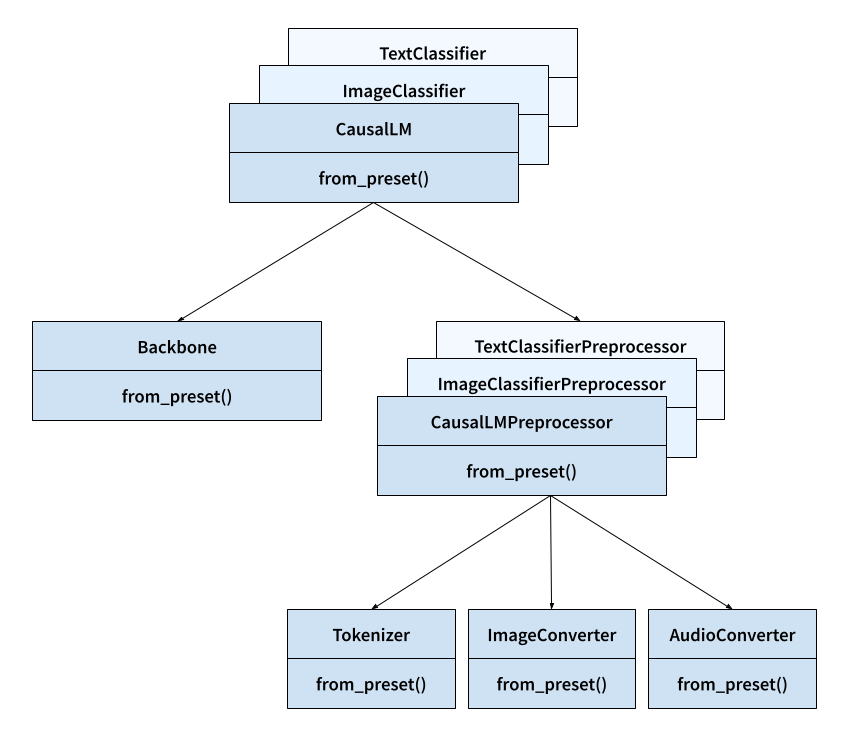
在我们开始之前,让我们先了解一下 KerasHub 库中将要使用的关键类。
- 任务 (Task):例如
keras_hub.models.CausalLM、keras_hub.models.ImageClassifier和keras_hub.models.TextClassifier。- 作用:任务将原始图像、音频和文本输入映射到模型预测。
- 重要性:任务是 KerasHub API 的最高级别入口点。它将预处理和建模封装在一个易于使用的类中。任务可用于微调和推理。
- 包含:
backbone和preprocessor。 - 继承自:
keras.Model。
- 主干 (Backbone):
keras_hub.models.Backbone。- 作用:将预处理后的张量输入映射到模型的潜在空间。
- 重要性:主干以一种不针对任何特定任务的方式封装了预训练模型的架构和参数。主干可以与任意的预处理和“头部”层(将密集特征映射到预测)结合,以完成任何 ML 任务。
- 继承自:
keras.Model。
- 预处理器 (Preprocessor):例如,
keras_hub.models.CausalLMPreprocessor、keras_hub.models.ImageClassifierPreprocessor和keras_hub.models.TextClassifierPreprocessor。- 作用:预处理器将原始图像、音频和文本输入映射到预处理后的张量输入。
- 重要性:预处理层以独立的方式封装了所有任务特定的预处理(例如,图像大小调整和文本分词),可用于预先计算预处理后的输入。请注意,如果您使用的是高级任务类,则此预处理默认已包含在内。
- 包含:
tokenizer、audio_converter和/或image_converter。 - 继承自:
keras.layers.Layer。
- 分词器 (Tokenizer):
keras_hub.tokenizers.Tokenizer。- 作用:将字符串转换为 token ID 序列。
- 重要性:字符串的原始字节是文本输入的低效表示,因此我们首先将字符串输入映射到整数 token ID。此类封装了字符串到整数的映射以及反向映射(通过
detokenize()方法)。 - 继承自:
keras.layers.Layer。
- 图像转换器 (ImageConverter):
keras_hub.layers.ImageConverter。- 作用:调整图像输入的大小并重新缩放。
- 重要性:图像模型通常需要将图像输入归一化到特定范围,或将输入调整到特定大小。此类封装了图像特定的预处理。
- 继承自:
keras.layers.Layer。
- 音频转换器 (AudioConverter):
keras_hub.layers.AudioConverter。- 作用:将原始音频转换为模型就绪的输入。
- 重要性:音频模型通常需要对原始音频输入进行预处理,例如通过计算音频信号的频谱图。此类以易于使用的层封装了图像特定的预处理。
- 继承自:
keras.layers.Layer。
此处列出的所有类都有一个 from_preset() 构造函数,它将使用给定预训练模型标识符的权重和状态来实例化组件。例如,keras_hub.tokenizers.Tokenizer.from_preset("gemma2_2b_en") 将创建一个使用 Gemma2 分词器词汇表进行分词的层。
下图展示了所有这些核心类如何交互。箭头表示组合而非继承(例如,任务拥有主干)。
对图像进行分类

足够的设置!让我们来玩转预训练模型。让我们加载一张加州鹌鹑的测试图像并对其进行分类。
import keras
import numpy as np
import matplotlib.pyplot as plt
image_url = "https://upload.wikimedia.org/wikipedia/commons/a/aa/California_quail.jpg"
image_path = keras.utils.get_file(origin=image_url)
image = keras.utils.load_img(image_path)
plt.imshow(image)

我们可以使用在 ImageNet-1k 数据集上训练的 ResNet 视觉模型。此模型将为每个输入样本提供一个输出标签,范围为 [0, 1000),其中每个标签对应于一个真实的词语实体,例如“奶罐”或“porcupine”。该数据集实际上有一个针对鹌鹑的特定标签,索引为 85。让我们下载模型并预测一个标签。
import keras_hub
image_classifier = keras_hub.models.ImageClassifier.from_preset(
"resnet_50_imagenet",
activation="softmax",
)
batch = np.array([image])
image_classifier.preprocessor.image_size = (224, 224)
preds = image_classifier.predict(batch)
preds.shape
1/1 ━━━━━━━━━━━━━━━━━━━━ 2s 2s/step
(1, 1000)
这些 ImageNet 标签不是很“人类可读”,因此我们可以使用内置的实用函数将预测解码为一组类名。
keras_hub.utils.decode_imagenet_predictions(preds)
[[('quail', 0.9996534585952759),
('prairie_chicken', 8.45497488626279e-05),
('partridge', 1.4000976079842076e-05),
('black_grouse', 7.407367775158491e-06),
('bullet_train', 7.323932550207246e-06)]]
看起来不错!模型权重已成功下载,并且我们几乎可以确定地预测了鹌鹑图像的正确分类标签。
这是我们上面 API 快速入门中提到的高级任务 API 的第一个示例。keras_hub.models.ImageClassifier 是一个用于图像分类的任务,可以与多种不同的模型架构(ResNet、VGG、MobileNet 等)一起使用。您可以在 Kaggle 上查看 Keras 团队直接提供的模型的完整列表。
任务只是 keras.Model 的一个子类——您可以使用 fit()、compile() 和 save(),与任何其他模型一样操作我们的 classifier 对象。但任务带有一些 KerasHub 库提供的额外功能。第一个也是最重要的功能是 from_preset(),这是一个您将在 KerasHub 的许多类上看到的特殊构造函数。
预设 (Preset) 是一个模型状态目录。它定义了我们应该加载的架构以及与之匹配的预训练权重。from_preset() 允许我们从多个不同位置加载预设目录:
- 本地目录。
- Kaggle 模型中心。
- HuggingFace 模型中心。
您可以查看 keras_hub.models.ImageClassifier.from_preset 的文档,以更好地理解从预设构建 Keras 模型时的所有选项。
所有任务都使用两个主要子对象:一个 keras_hub.models.Backbone 和一个 keras_hub.layers.Preprocessor。您可能已经熟悉“主干”这个术语,尤其是在计算机视觉领域,它通常用于描述将图像映射到潜在空间的特征提取网络。KerasHub 主干是这种概念的泛化,我们用它来指代任何没有任务特定头的预训练模型。也就是说,KerasHub 主干将原始图像、音频和文本(或这些输入的组合)映射到预训练模型的潜在空间。然后,我们可以根据我们想要用模型做什么,将这个潜在空间映射到任意数量的任务特定输出。
预处理器 (Preprocessor) 只是一个 Keras 层,它执行特定任务的所有预处理。在我们的例子中,预处理将调整我们输入图像的大小并使用一些 ImageNet 特定的均值和方差数据将其重新缩放到 [0, 1] 范围。让我们连续调用任务的预处理器和主干,看看输入形状会发生什么。
print("Raw input shape:", batch.shape)
resized_batch = image_classifier.preprocessor(batch)
print("Preprocessed input shape:", resized_batch.shape)
hidden_states = image_classifier.backbone(resized_batch)
print("Latent space shape:", hidden_states.shape)
Raw input shape: (1, 557, 707, 3)
Preprocessed input shape: (1, 224, 224, 3)
Latent space shape: (1, 7, 7, 2048)
我们的原始图像在预处理过程中被缩放为 (224, 224),最后被缩小为 (7, 7) 的图像,其中包含 2048 个特征向量——这是 ResNet 模型的潜在空间。请注意,ResNet 实际上可以处理任意大小的图像,但如果您的图像大小与预训练数据差异很大,性能最终会下降。如果您想禁用预处理层中的大小调整,可以运行 image_classifier.preprocessor.image_size = None。
如果您想知道加载的任务的确切结构,可以像使用任何 Keras 模型一样使用 model.summary()。任务的模型摘要将包含有关模型预处理的额外信息。
image_classifier.summary()
Preprocessor: "res_net_image_classifier_preprocessor"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Config ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ res_net_image_converter │ Image size: (224, 224) │ │ (ResNetImageConverter) │ │ └──────────────────────────────────────────────┴───────────────────────────────┘
Model: "res_net_image_classifier"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer (InputLayer) │ (None, None, None, 3) │ 0 │ ├───────────────────────────────────┼──────────────────────────┼───────────────┤ │ res_net_backbone (ResNetBackbone) │ (None, None, None, 2048) │ 23,561,152 │ ├───────────────────────────────────┼──────────────────────────┼───────────────┤ │ pooler (GlobalAveragePooling2D) │ (None, 2048) │ 0 │ ├───────────────────────────────────┼──────────────────────────┼───────────────┤ │ output_dropout (Dropout) │ (None, 2048) │ 0 │ ├───────────────────────────────────┼──────────────────────────┼───────────────┤ │ predictions (Dense) │ (None, 1000) │ 2,049,000 │ └───────────────────────────────────┴──────────────────────────┴───────────────┘
Total params: 25,610,152 (97.69 MB)
Trainable params: 25,557,032 (97.49 MB)
Non-trainable params: 53,120 (207.50 KB)
使用 LLM 生成文本

接下来,让我们尝试使用和生成文本。我们可以用于生成文本的任务是 keras_hub.models.CausalLM(LM 是 Language Model 的缩写)。让我们下载 20 亿参数的 Gemma 2 模型并尝试一下。
由于这是一个比我们刚刚下载的 ResNet 模型大 100 倍的模型,我们需要更小心地处理 GPU 内存使用。我们可以使用半精度类型将我们大约 25 亿的每个参数加载为两个字节的浮点数,而不是四个。要做到这一点,我们可以将 dtype 传递给 from_preset() 构造函数。from_preset() 会将任何 kwargs 转发给类的主要构造函数,因此您可以传递适用于所有 Keras 层的 kwargs,例如 dtype、trainable 和 name。
causal_lm = keras_hub.models.CausalLM.from_preset(
"gemma2_instruct_2b_en",
dtype="bfloat16",
)
我们刚刚加载的模型是 Gemma 的指令微调版本,这意味着该模型经过了进一步的聊天微调。只要我们遵循模型训练时使用的特定文本模板,我们就可以利用这些功能。这些特殊 token 因模型而异,并且很难跟踪,Kaggle 模型页面将包含此类详细信息。
CausalLM 带有一个名为 generate() 的额外函数,可用于在循环中生成预测 token 并将其解码为字符串。
template = "<start_of_turn>user\n{question}<end_of_turn>\n<start_of_turn>model"
question = """Write a python program to generate the first 1000 prime numbers.
Just show the actual code."""
print(causal_lm.generate(template.format(question=question), max_length=512))
<start_of_turn>user
Write a python program to generate the first 1000 prime numbers.
Just show the actual code.<end_of_turn>
<start_of_turn>model
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
count = 0
number = 2
primes = []
while count < 1000:
if is_prime(number):
primes.append(number)
count += 1
number += 1
print(primes)
<end_of_turn>
请注意,在 Jax 和 TensorFlow 后端上,此 generate() 函数是经过编译的,因此第二次调用以相同的 max_length 时,速度会快得多。KerasHub 将使用 Jax 和 TensorFlow 来计算可重用的、优化的生成计算图。
question = "Share a very simple brownie recipe."
print(causal_lm.generate(template.format(question=question), max_length=512))
<start_of_turn>user
Share a very simple brownie recipe.<end_of_turn>
<start_of_turn>model
---
## Super Simple Brownies
**Ingredients:**
* 1 cup (2 sticks) unsalted butter, melted
* 2 cups granulated sugar
* 4 large eggs
* 1 teaspoon vanilla extract
* 1 cup all-purpose flour
* 1/2 cup unsweetened cocoa powder
* 1/4 teaspoon salt
**Instructions:**
1. Preheat oven to 350°F (175°C). Grease and flour a 9x13 inch baking pan.
2. In a large bowl, whisk together the melted butter and sugar until smooth.
3. Beat in the eggs one at a time, then stir in the vanilla extract.
4. In a separate bowl, whisk together the flour, cocoa powder, and salt.
5. Gradually add the dry ingredients to the wet ingredients, mixing until just combined. Do not overmix.
6. Pour the batter into the prepared pan and spread evenly.
7. Bake for 25-30 minutes, or until a toothpick inserted into the center comes out with a few moist crumbs attached.
8. Let cool completely before cutting and serving.
**Tips:**
* For extra fudgy brownies, underbake them slightly.
* Add chocolate chips, nuts, or other mix-ins to the batter for a personalized touch.
* Serve with a scoop of ice cream or whipped cream for a decadent treat.
Enjoy!
<end_of_turn>
与我们的图像分类器一样,我们可以使用模型摘要来查看任务设置的详细信息,包括预处理。
causal_lm.summary()
Preprocessor: "gemma_causal_lm_preprocessor"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Config ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ gemma_tokenizer (GemmaTokenizer) │ Vocab size: 256,000 │ └──────────────────────────────────────────────┴───────────────────────────────┘
Model: "gemma_causal_lm"
┏━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├───────────────────────┼───────────────────┼─────────────┼────────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├───────────────────────┼───────────────────┼─────────────┼────────────────────┤ │ gemma_backbone │ (None, None, │ 2,614,341,… │ padding_mask[0][0… │ │ (GemmaBackbone) │ 2304) │ │ token_ids[0][0] │ ├───────────────────────┼───────────────────┼─────────────┼────────────────────┤ │ token_embedding │ (None, None, │ 589,824,000 │ gemma_backbone[0]… │ │ (ReversibleEmbedding) │ 256000) │ │ │ └───────────────────────┴───────────────────┴─────────────┴────────────────────┘
Total params: 2,614,341,888 (4.87 GB)
Trainable params: 2,614,341,888 (4.87 GB)
Non-trainable params: 0 (0.00 B)
我们的文本预处理包括一个分词器,这是所有 KerasHub 模型处理输入文本的方式。让我们尝试直接使用它来更好地了解其工作原理。所有分词器都包含 tokenize() 和 detokenize() 方法,用于将字符串映射到整数序列以及将整数序列映射到字符串。直接用 tokenizer(inputs) 调用该层等同于调用 tokenizer.tokenize(inputs)。
tokenizer = causal_lm.preprocessor.tokenizer
tokens_ids = tokenizer.tokenize("The quick brown fox jumps over the lazy dog.")
print(tokens_ids)
string = tokenizer.detokenize(tokens_ids)
print(string)
[ 651 4320 8426 25341 36271 1163 573 27894 5929 235265]
The quick brown fox jumps over the lazy dog.
CausalLM 模型的 generate() 函数涉及一个采样步骤。Gemma 模型将被调用一次以生成我们想要的每个 token,并返回所有 token 的概率分布。然后,对该分布进行采样以选择序列中的下一个 token。
对于 Gemma 模型,我们默认使用贪婪采样,这意味着我们在每一步简单地选择模型最可能的输出。但我们实际上可以通过对所有 Keras 模型上的标准 compile 函数使用额外的 sampler 参数来控制此过程。让我们尝试一下。
causal_lm.compile(
sampler=keras_hub.samplers.TopKSampler(k=10, temperature=2.0),
)
question = "Share a very simple brownie recipe."
print(causal_lm.generate(template.format(question=question), max_length=512))
<start_of_turn>user
Share a very simple brownie recipe.<end_of_turn>
<start_of_turn>model ## Ultimate Simple Brownies
This recipe requires NO oven or special equipment! Just microwave, mixing, and a few moments!
**Yields:** 6 large brownies
**Prep time:** 7 minutes
**Cook time:** 6-9 minutes, depending on your microwave
**What you need:**
* 3 ounces (about 2-3 tablespoons) chocolate chips
* 1/4 cup butter
* 1 large egg
* 1/2 cup granulated sugar
* 9 tablespoons all-purpose flour
**Optional Add-Ins (for extra fun):**
* 1/2 teaspoon vanilla
* 1/4 cup chopped walnuts or pecans
**Instructions:**
1. Place all microwave-safe mixing bowl ingredients:
- Chocolate Chips 🍫
- Butter 🧈
- Flour 🗲
- Egg (beaten!)
(You can add the optional add-INS like chopped nuts/extra vanilla, now is the good place to!)
2. Put all that in your microwave (microwave-safe dish or a heat-safe mug is fine!)
3. **Cook on:** Medium-high, stirring halfway.
* Time depends on your microwave, so keep checking, but aim for 6-9 minutes (if no stirring at least 8 mins). You want a thick, almost chewy-texture.
**To serve:** Cut up your brownies immediately and savor this classic treat. You'd also need a tall glass of cold milk or coffee (or both, if you've really enjoyed it).
Let me know if you want to experiment with a different chocolate or add-ins to make it even sweeter. Enjoy! 😉
<end_of_turn>
在这里,我们使用了 Top-K 采样器,这意味着我们将随机采样由每一步仅查看前 10 个预测 token 形成的局部分布。我们还传递了 2 的 temperature,它会在我们采样之前使预测分布变得平缓。
总而言之,每次生成输出时,我们将更广泛地探索模型的分布。生成现在将成为一个随机过程,每次重新运行 generate 我们都会得到不同的结果。我们可以注意到,结果比贪婪搜索感觉“更自由”——有更多细微的错误,一致性较差,并且有令人怀疑的建议(微波棕榈酰胺)。
您可以在 keras_hub.samplers 中查看 Keras 支持的所有采样器。
在进入下一节之前,让我们释放掉大型 Gemma 模型占用的内存。
del causal_lm
微调并发布图像分类器

现在我们已经尝试了对图像和文本进行推理,让我们尝试进行训练。我们将使用之前的 ResNet 图像分类器,并在简单的猫狗数据集上对其进行微调。我们可以从下载和提取数据开始。
import pathlib
extract_dir = keras.utils.get_file(
"cats_vs_dogs",
"https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip",
extract=True,
)
data_dir = pathlib.Path(extract_dir) / "PetImages"
在使用大量真实图像数据时,损坏的图像很常见。让我们过滤掉头信息中不包含字符串“JFIF”的编码错误的图像。
num_skipped = 0
for path in data_dir.rglob("*.jpg"):
with open(path, "rb") as file:
is_jfif = b"JFIF" in file.peek(10)
if not is_jfif:
num_skipped += 1
os.remove(path)
print(f"Deleted {num_skipped} images.")
Deleted 1590 images.
我们可以使用 keras.utils.image_dataset_from_directory 加载数据集。这里需要注意的一个重要事项是,train_ds 和 val_ds 都将作为 tf.data.Dataset 对象返回,包括在 torch 和 jax 后端上。
KerasHub 将使用 tf.data 作为运行多线程 CPU 预处理的默认 API。 tf.data 是一个强大的用于训练输入管道的 API,它可以轻松扩展到复杂的多主机训练作业。使用它并不会限制您选择的后端,tf.data.Dataset 可以作为普通 numpy 数据的迭代器,并传递给任何 Keras 后端的 fit()。
train_ds, val_ds = keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="both",
seed=1337,
image_size=(256, 256),
batch_size=32,
)
Found 23410 files belonging to 2 classes.
Using 18728 files for training.
Using 4682 files for validation.
最简单的情况下,训练我们的分类器可能就是用我们的数据集调用模型的 fit()。但为了让这个例子更有趣一点,让我们展示一下如何自定义任务中的预处理。
在第一个示例中,我们看到了默认情况下,我们的 ResNet 模型的预处理如何调整输入大小并重新缩放输入。在创建模型时,可以自定义此预处理。我们可以使用 Keras 的图像预处理层来创建一个 keras.layers.Pipeline,该层将重新缩放、随机翻转并随机旋转我们的输入图像。这些随机图像增强将使我们较小的数据集能够充当更大、更多样化的数据集。让我们尝试一下。
preprocessor = keras.layers.Pipeline(
[
keras.layers.Rescaling(1.0 / 255),
keras.layers.RandomFlip("horizontal"),
keras.layers.RandomRotation(0.2),
]
)
现在我们已经创建了一个新的预处理层,我们可以将其在 from_preset() 构造函数中传递给 ImageClassifier。我们还可以传递 num_classes=2 来匹配我们“猫”和“狗”的两个标签。当像这样指定 num_classes 时,我们模型头部的权重将被随机初始化,而不是包含我们 1000 类图像分类的权重。
image_classifier = keras_hub.models.ImageClassifier.from_preset(
"resnet_50_imagenet",
activation="softmax",
num_classes=2,
preprocessor=preprocessor,
)
请注意,如果您想在 Keras 之外预处理输入数据,只需将 preprocessor=None 传递给任务的 from_preset() 调用即可。在这种情况下,KerasHub 将不进行任何预处理,您可以自由地使用任何库或工作流对数据进行预处理,然后再将数据传递给 fit()。
接下来,我们可以编译我们的模型以进行微调。KerasHub 任务只是一个普通的 keras.Model,带有一些额外功能,因此我们可以像往常一样为分类任务 compile()。
image_classifier.compile(
optimizer=keras.optimizers.Adam(1e-4),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
至此,我们只需运行 fit()。图像分类器将在训练模型时自动将我们的预处理应用于每个批次。
image_classifier.fit(
train_ds,
validation_data=val_ds,
epochs=3,
)
Epoch 1/3
586/586 ━━━━━━━━━━━━━━━━━━━━ 0s 122ms/step - accuracy: 0.8869 - loss: 0.2921
Epoch 2/3
586/586 ━━━━━━━━━━━━━━━━━━━━ 65s 105ms/step - accuracy: 0.9858 - loss: 0.0393 - val_accuracy: 0.9912 - val_loss: 0.0234
Epoch 3/3
586/586 ━━━━━━━━━━━━━━━━━━━━ 57s 96ms/step - accuracy: 0.9897 - loss: 0.0289 - val_accuracy: 0.9930 - val_loss: 0.0206
<keras.src.callbacks.history.History at 0x787e77fb2550>
经过三个 epoch 的数据训练,我们在猫狗验证数据集上实现了 99% 的准确率。这不足为奇,因为我们最初的 ImageNet 预训练权重已经能够单独对某些猫狗品种进行分类。
现在我们有了一个微调的模型,让我们尝试保存它。您可以通过运行 task.save_to_preset() 来为任何任务创建一个具有微调模型的新保存的预设。
image_classifier.save_to_preset("cats_vs_dogs")
KerasHub 最强大的功能之一是能够将模型上传到 Kaggle 或 HuggingFace 模型中心并与他人共享。 keras_hub.upload_preset 允许您上传已保存的预设。
在这种情况下,我们将上传到 Kaggle。我们已经提前通过身份验证 Kaggle 以下载 Gemma 模型。运行以下单元格将向 Kaggle 上传一个新模型。
from google.colab import userdata
username = userdata.get("KAGGLE_USERNAME")
keras_hub.upload_preset(
f"kaggle://{username}/resnet/keras/cats_vs_dogs",
"cats_vs_dogs",
)
Uploading Model https://www.kaggle.com/models/matthewdwatson/resnet/keras/cats_vs_dogs ...
Upload successful: cats_vs_dogs/task.json (5KB)
Upload successful: cats_vs_dogs/task.weights.h5 (270MB)
Upload successful: cats_vs_dogs/metadata.json (157B)
Upload successful: cats_vs_dogs/model.weights.h5 (90MB)
Upload successful: cats_vs_dogs/config.json (841B)
Upload successful: cats_vs_dogs/preprocessor.json (3KB)
Your model instance version has been created.
Files are being processed...
See at: https://www.kaggle.com/models/matthewdwatson/resnet/keras/cats_vs_dogs
让我们看一下我们数据集中的一张测试图像。
image = keras.utils.load_img(data_dir / "Cat" / "6779.jpg")
plt.imshow(image)

如果我们等待几分钟让模型在 Kaggle 端完成上传处理,我们可以继续下载我们刚刚创建的模型并使用它来对此测试图像进行分类。
image_classifier = keras_hub.models.ImageClassifier.from_preset(
f"kaggle://{username}/resnet/keras/cats_vs_dogs",
)
print(image_classifier.predict(np.array([image])))
1/1 ━━━━━━━━━━━━━━━━━━━━ 2s 2s/step
[[9.999286e-01 7.135461e-05]]
恭喜您使用 KerasHub 上传了您的第一个模型!如果您想与他人分享您的作品,可以访问我们上传模型时打印出的模型链接,并在设置中将模型设为公开。
让我们删除此模型以释放内存,然后再继续我们本指南的最后一个示例。
del image_classifier
构建自定义文本分类器

作为本入门指南的最后一个示例,让我们看一下如何从更底层的 Keras 和 KerasHub 组件构建自定义模型。我们将构建一个文本分类器来将 IMDb 数据集中的电影评论分类为正面或负面。
让我们下载数据集。
extract_dir = keras.utils.get_file(
"imdb_reviews",
origin="https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz",
extract=True,
)
data_dir = pathlib.Path(extract_dir) / "aclImdb"
IMDb 数据集包含大量未标记的电影评论。我们在这里不需要它们,可以直接删除。
import shutil
shutil.rmtree(data_dir / "train" / "unsup")
接下来,我们可以使用 keras.utils.text_dataset_from_directory 加载数据。与上面创建图像数据集一样,返回的数据集将是 tf.data.Dataset 对象。
raw_train_ds = keras.utils.text_dataset_from_directory(
data_dir / "train",
batch_size=2,
)
raw_val_ds = keras.utils.text_dataset_from_directory(
data_dir / "test",
batch_size=2,
)
Found 25000 files belonging to 2 classes.
Found 25000 files belonging to 2 classes.
KerasHub 被设计为一个分层 API。在最高级别,任务旨在轻松快速地解决问题。我们也可以继续使用任务 API,并创建一个 keras_hub.models.TextClassifier 来进行 BERT 等文本分类模型,并在大约 10 行代码中进行微调。
相反,为了让最后一个例子更有趣一点,让我们展示一下如何使用更低级别的 API 组件来做一些库中没有直接内置的事情。我们将使用之前使用的 Gemma 2 模型,它通常用于生成文本,并对其进行修改以输出分类预测。
使用生成模型进行分类的一种常见方法是继续在生成上下文中对其进行使用,通过提示输入评论和一个问题(“这篇评论是正面还是负面?”)。但创建一个实际的分类器更有用,如果您想要一个与您的标签相关的实际概率分数。
我们不是通过 CausalLM 任务加载 Gemma 2 模型,而是加载两个更低级别的组件:一个主干 (backbone) 和一个分词器 (tokenizer)。与我们到目前为止使用的任务类非常相似,keras_hub.models.Backbone 和 keras_hub.tokenizers.Tokenizer 都具有用于加载预训练模型的 from_preset() 构造函数。如果您正在运行此代码,您会注意到不必等待下载,因为我们第二次使用该模型,权重文件会在我们第一次使用该模型时被缓存到本地。
tokenizer = keras_hub.tokenizers.Tokenizer.from_preset(
"gemma2_instruct_2b_en",
)
backbone = keras_hub.models.Backbone.from_preset(
"gemma2_instruct_2b_en",
)
我们在本指南的第二个示例中看到了分词器的工作原理。我们可以使用它来将字符串输入映射到 token ID,其方式与 Gemma 模型的预训练权重相匹配。
主干会将 token ID 序列映射到模型潜在空间中的嵌入 token 序列。我们可以使用这种丰富的表示来构建分类器。
让我们先定义一个自定义预处理例程。keras_hub.layers 包含一系列建模和预处理层,包括一些用于 token 预处理的层。我们可以使用 keras_hub.layers.StartEndPacker,它会在每篇评论的开头添加一个特殊起始 token,在结尾添加一个特殊结束 token,最后将每篇评论截断或填充到固定长度。
如果我们结合我们的 tokenizer,我们可以构建一个预处理函数,它将输出 token ID 批次,形状为 (batch_size, sequence_length)。我们还应该输出一个填充掩码 (padding mask),用于标记哪些 token 是填充 token,以便我们以后可以排除这些位置,避免在 Transformer 的注意力计算中出现问题。KerasNLP 中的大多数 Transformer 主干都接受 "padding_mask" 输入。
packer = keras_hub.layers.StartEndPacker(
start_value=tokenizer.start_token_id,
end_value=tokenizer.end_token_id,
pad_value=tokenizer.pad_token_id,
sequence_length=None,
)
def preprocess(x, y=None, sequence_length=256):
x = tokenizer(x)
x = packer(x, sequence_length=sequence_length)
x = {
"token_ids": x,
"padding_mask": x != tokenizer.pad_token_id,
}
return keras.utils.pack_x_y_sample_weight(x, y)
定义了预处理后,我们就可以简单地使用 tf.data.Dataset.map 将我们的预处理应用于输入数据。
train_ds = raw_train_ds.map(preprocess, num_parallel_calls=16)
val_ds = raw_val_ds.map(preprocess, num_parallel_calls=16)
next(iter(train_ds))
({'token_ids': <tf.Tensor: shape=(2, 256), dtype=int32, numpy=
array([[ 2, 94300, 1185, ... 0]],
dtype=int32)>,
'padding_mask': <tf.Tensor: shape=(2, 256), dtype=bool, numpy=
array([[ True, True, True, ... False]])>},
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([1, 0], dtype=int32)>)
在 25 亿参数模型上运行微调比我们之前训练的图像分类器要昂贵得多,这仅仅是因为这个模型比 ResNet 大 100 倍!为了稍微加快速度,让我们将训练数据的大小减小到原始大小的十分之一。当然,这会牺牲一些性能,与完全训练相比,但它将使我们的指南保持快速运行。
train_ds = train_ds.take(1000)
val_ds = val_ds.take(1000)
接下来,我们需要为我们的主干模型附加一个分类头部。一般来说,文本 Transformer 主干将输出一个形状为 (batch_size, sequence_length, hidden_dim) 的张量。在对此输入进行分类时,我们需要做的一件主要事情是在序列维度上进行池化,以便每个输入示例只有一个特征向量。
由于 Gemma 模型是生成模型,信息仅从序列的左到右传递。能够“看到”整个电影评论输入的唯一 token 表示是每篇评论的最后一个 token。我们可以编写一个简单的池化层来实现这一点——我们将简单地抓取每个输入序列的最后一个非填充位置。编写这样的层没有特殊的流程,我们可以正常使用 Keras 和 keras.ops。
from keras import ops
class LastTokenPooler(keras.layers.Layer):
def call(self, inputs, padding_mask):
end_positions = ops.sum(padding_mask, axis=1, keepdims=True) - 1
end_positions = ops.cast(end_positions, "int")[:, :, None]
outputs = ops.take_along_axis(inputs, end_positions, axis=1)
return ops.squeeze(outputs, axis=1)
有了这个池化层,我们就可以编写我们的 Gemma 分类器了。KerasHub 中的所有任务和主干模型都是 函数式模型,因此我们可以轻松地操纵模型结构。我们将用我们的输入调用主干,添加我们新的池化层,最后添加一个带有“relu”激活的小前馈网络。让我们尝试一下。
inputs = backbone.input
x = backbone(inputs)
x = LastTokenPooler(
name="pooler",
)(x, inputs["padding_mask"])
x = keras.layers.Dense(
2048,
activation="relu",
name="pooled_dense",
)(x)
x = keras.layers.Dropout(
0.1,
name="output_dropout",
)(x)
outputs = keras.layers.Dense(
2,
activation="softmax",
name="output_dense",
)(x)
text_classifier = keras.Model(inputs, outputs)
text_classifier.summary()
Model: "functional"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ gemma_backbone │ (None, None, │ 2,614,341… │ padding_mask[0][… │ │ (GemmaBackbone) │ 2304) │ │ token_ids[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ pooler │ (None, 2304) │ 0 │ gemma_backbone[0… │ │ (LastTokenPooler) │ │ │ padding_mask[0][… │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ pooled_dense │ (None, 2048) │ 4,720,640 │ pooler[0][0] │ │ (Dense) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ output_dropout │ (None, 2048) │ 0 │ pooled_dense[0][… │ │ (Dropout) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ output_dense │ (None, 2) │ 4,098 │ output_dropout[0… │ │ (Dense) │ │ │ │ └─────────────────────┴───────────────────┴────────────┴───────────────────┘
Total params: 2,619,066,626 (9.76 GB)
Trainable params: 2,619,066,626 (9.76 GB)
Non-trainable params: 0 (0.00 B)
在训练之前,我们应该再使用一个技巧来让这段代码在免费层级的 colab GPU 上运行。从我们的模型摘要中可以看到,我们的模型占用了将近 10GB 的空间。优化器在训练期间需要创建每个参数的多个副本,这使得我们的模型在训练期间的总空间接近 30 或 40GB。
这会导致许多 GPU 出现 OOM(内存不足)错误。一个有用的技巧是为我们的主干启用 LoRA。LoRA 是一种冻结整个模型的方法,仅训练大型权重矩阵的低参数分解。您可以在此 Keras 示例中了解更多关于 LoRA 的信息。让我们尝试启用它并重新打印我们的摘要。
backbone.enable_lora(4)
text_classifier.summary()
Model: "functional"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩ │ padding_mask │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ token_ids │ (None, None) │ 0 │ - │ │ (InputLayer) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ gemma_backbone │ (None, None, │ 2,617,270… │ padding_mask[0][… │ │ (GemmaBackbone) │ 2304) │ │ token_ids[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ pooler │ (None, 2304) │ 0 │ gemma_backbone[0… │ │ (LastTokenPooler) │ │ │ padding_mask[0][… │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ pooled_dense │ (None, 2048) │ 4,720,640 │ pooler[0][0] │ │ (Dense) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ output_dropout │ (None, 2048) │ 0 │ pooled_dense[0][… │ │ (Dropout) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ output_dense │ (None, 2) │ 4,098 │ output_dropout[0… │ │ (Dense) │ │ │ │ └─────────────────────┴───────────────────┴────────────┴───────────────────┘
Total params: 2,621,995,266 (9.77 GB)
Trainable params: 7,653,378 (29.20 MB)
Non-trainable params: 2,614,341,888 (9.74 GB)
启用 LoRA 后,我们的模型可训练参数从 10GB 减少到仅 20MB。这意味着优化器变量使用的空间将不再是问题。
设置好所有这些之后,我们可以像往常一样编译和训练我们的模型。
text_classifier.compile(
optimizer=keras.optimizers.Adam(5e-5),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
text_classifier.fit(
train_ds,
validation_data=val_ds,
)
1000/1000 ━━━━━━━━━━━━━━━━━━━━ 295s 285ms/step - accuracy: 0.7733 - loss: 0.6511 - val_accuracy: 0.9370 - val_loss: 0.2814
<keras.src.callbacks.history.History at 0x787e103ae010>
我们能够在此电影评论情感分类问题上实现超过 ~93% 的准确率。考虑到我们仅使用了原始数据集的十分之一进行训练,这不算差。
总而言之,本示例中创建的 backbone 和 tokenizer 使我们能够访问预训练 Gemma 检查点的全部功能,而不会限制我们对它们的使用方式。这是 KerasHub API 的一个核心目标。简单的流程应该很容易,当您深入研究时,您将获得一个高度可定制的构建块集。
进一步探索
这只是 KerasHub 功能的冰山一角。
本指南展示了 KerasHub 库提供的一些高级任务,但还有许多我们在此未涵盖的任务。例如,尝试 使用 Stable Diffusion 生成图像。
KerasHub 最显著的优势在于它提供了灵活性,可以将预训练的构建块与 Keras 3 的全部功能结合起来。您可以使用 keras.distribution API 在 TPU 上使用模型并行训练大型 LLM。您可以使用 Keras 的 量化方法来量化模型。您可以编写自定义训练循环,甚至混合使用直接的 Jax、Torch 或 TensorFlow 调用。
请参阅 keras.io/keras_hub 获取完整的指南和示例列表,以便继续深入了解该库。