使用深度交叉网络进行排序
作者: Abheesht Sharma, Fabien Hertschuh
创建日期 2025/04/28
最后修改日期 2025/04/28
描述: 使用深度交叉网络 (DCN) 对电影进行排序。

简介
本教程演示了如何使用深度与交叉网络 (DCN) 有效地学习特征交叉。在深入示例之前,让我们简要讨论一下特征交叉。
想象一下,我们正在为搅拌机构建一个推荐系统。单独的特征可能包括客户过去的购买历史(例如,purchased_bananas、purchased_cooking_books)或地理位置。然而,同时购买香蕉和烹饪书籍的客户比只购买其中一项的客户更有可能对搅拌机感兴趣。purchased_bananas 和 purchased_cooking_books 的组合是一个特征交叉。特征交叉捕获单个特征之间的交互信息,提供了比单独的特征更丰富的上下文。

学习有效的特征交叉带来了许多挑战。在 Web 规模的应用中,数据通常是分类的,导致高维和稀疏的特征空间。在这样的环境中识别有影响力的特征交叉通常依赖于手动特征工程或计算成本很高的穷举搜索。虽然传统的前馈多层感知器 (MLP) 是通用的函数逼近器,但它们通常难以有效地学习二阶或三阶特征交互。
深度与交叉网络 (DCN) 架构旨在更有效地学习显式和有界阶数的特征交叉。它包含三个主要组件:一个输入层(通常是嵌入层)、一个用于建模显式特征交互的交叉网络,以及一个用于捕获隐式交互的深度网络。
交叉网络是 DCN 的核心。它在每一层显式执行特征交叉,特征交互的最高多项式次数随深度增加。下图显示了(i+1)-th 交叉层。

深度网络是一个标准的前馈多层感知器 (MLP)。然后将这两个网络组合起来形成 DCN。存在两种常见的组合策略:堆叠结构,其中深度网络放置在交叉网络之上;并行结构,其中它们并行运行。

|

|
现在我们对 DCN 有了些了解,让我们开始编写代码。我们将首先在一个玩具数据集上训练 DCN,并演示模型确实已经学习了重要的特征交叉。
让我们将后端设置为 JAX,并整理好导入。
!pip install -q keras-rs
import os
os.environ["KERAS_BACKEND"] = "jax" # `"tensorflow"`/`"torch"`
import keras
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from mpl_toolkits.axes_grid1 import make_axes_locatable
import keras_rs
我们还将定义将在示例中重复使用的变量。
TOY_CONFIG = {
"learning_rate": 0.01,
"num_epochs": 100,
"batch_size": 1024,
}
MOVIELENS_CONFIG = {
# features
"int_features": [
"movie_id",
"user_id",
"user_gender",
"bucketized_user_age",
],
"str_features": [
"user_zip_code",
"user_occupation_text",
],
# model
"embedding_dim": 8,
"deep_net_num_units": [192, 192, 192],
"projection_dim": 8,
"dcn_num_units": [192, 192],
# training
"learning_rate": 1e-2,
"num_epochs": 8,
"batch_size": 8192,
}
在这里,我们定义了一个辅助函数来可视化交叉层的权重,以便更好地理解其功能。此外,我们还定义了一个函数来编译、训练和评估给定的模型。
def visualize_layer(matrix, features):
plt.figure(figsize=(9, 9))
im = plt.matshow(np.abs(matrix), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
ax.set_xticklabels([""] + features, rotation=45, fontsize=5)
ax.set_yticklabels([""] + features, fontsize=5)
def train_and_evaluate(
learning_rate,
epochs,
train_data,
test_data,
model,
):
optimizer = keras.optimizers.AdamW(learning_rate=learning_rate)
loss = keras.losses.MeanSquaredError()
rmse = keras.metrics.RootMeanSquaredError()
model.compile(
optimizer=optimizer,
loss=loss,
metrics=[rmse],
)
model.fit(
train_data,
epochs=epochs,
verbose=0,
)
results = model.evaluate(test_data, return_dict=True, verbose=0)
rmse_value = results["root_mean_squared_error"]
return rmse_value, model.count_params()
def print_stats(rmse_list, num_params, model_name):
# Report metrics.
num_trials = len(rmse_list)
avg_rmse = np.mean(rmse_list)
std_rmse = np.std(rmse_list)
if num_trials == 1:
print(f"{model_name}: RMSE = {avg_rmse}; #params = {num_params}")
else:
print(f"{model_name}: RMSE = {avg_rmse} ± {std_rmse}; #params = {num_params}")
玩具示例
为了说明 DCN 的优势,让我们考虑一个简单的例子。假设我们有一个数据集用于模拟客户点击搅拌机广告的可能性。特征和标签定义如下
| 特征 / 标签 | 描述 | 范围 |
|---|---|---|
x1 = 国家 |
客户居住国家 | [0, 199] |
x2 = 香蕉 |
购买的香蕉数量 | [0, 23] |
x3 = 烹饪书 |
购买的烹饪书数量 | [0, 5] |
y |
搅拌机广告点击可能性 | - |
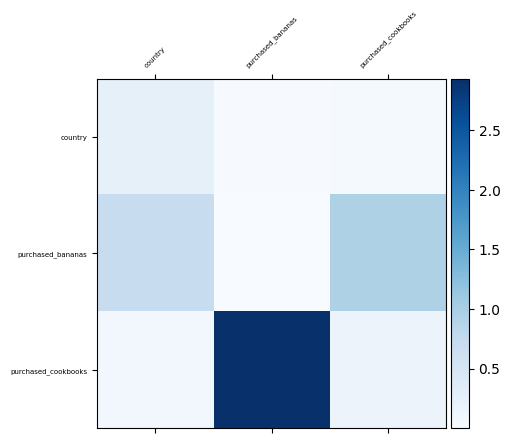
然后,我们让数据遵循以下潜在分布:y = f(x1, x2, x3) = 0.1x1 + 0.4x2 + 0.7x3 + 0.1x1x2 + 3.1x2x3 + 0.1x3^2。
此分布表明,点击可能性 (y) 不仅线性依赖于各个特征 (xi),而且还显著依赖于它们之间的乘法交互。在这种情况下,购买搅拌机的可能性 (y) 不仅受单独购买香蕉 (x2) 或烹饪书 (x3) 的影响,还显著受到购买香蕉和烹饪书 (x2x3) 交互的影响。
准备数据集
让我们根据上述方程创建合成数据,并形成训练-测试拆分。
def get_mixer_data(data_size=100_000):
country = np.random.randint(200, size=[data_size, 1]) / 200.0
bananas = np.random.randint(24, size=[data_size, 1]) / 24.0
cookbooks = np.random.randint(6, size=[data_size, 1]) / 6.0
x = np.concatenate([country, bananas, cookbooks], axis=1)
# Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * cookbooks
# Create 2nd-order cross terms.
y += (
0.1 * country * bananas
+ 3.1 * bananas * cookbooks
+ (0.1 * cookbooks * cookbooks)
)
return x, y
x, y = get_mixer_data(data_size=100_000)
num_train = 90_000
train_x = x[:num_train]
train_y = y[:num_train]
test_x = x[num_train:]
test_y = y[num_train:]
构建模型
为了展示推荐系统中交叉网络的优势,我们将将其性能与深度网络进行比较。由于我们的示例数据仅包含二阶特征交互,因此单层交叉网络就足够了。对于具有高阶交互的数据集,可以堆叠多个交叉层以形成多层交叉网络。我们将构建两个模型
- 具有单个交叉层的交叉网络。
- 具有更宽更深的前馈层的深度网络。
cross_network = keras.Sequential(
[
keras_rs.layers.FeatureCross(),
keras.layers.Dense(1),
]
)
deep_network = keras.Sequential(
[
keras.layers.Dense(512, activation="relu"),
keras.layers.Dense(256, activation="relu"),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dense(1),
]
)
模型训练
在训练模型之前,我们需要对数据集进行批处理。
train_ds = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(
TOY_CONFIG["batch_size"]
)
test_ds = tf.data.Dataset.from_tensor_slices((test_x, test_y)).batch(
TOY_CONFIG["batch_size"]
)
让我们训练这两个模型。请记住,出于简洁性,我们将 verbose=0 设置为 0,因此如果您长时间没有看到任何输出,请不要惊慌。
训练后,我们将在未见过的数据集上评估模型。我们将在此处报告均方根误差 (RMSE)。
我们观察到,与基于 ReLU 的 DNN 相比,交叉网络实现了显著更低的 RMSE,同时使用的参数也更少。这表明交叉网络在学习特征交互方面非常高效。
cross_network_rmse, cross_network_num_params = train_and_evaluate(
learning_rate=TOY_CONFIG["learning_rate"],
epochs=TOY_CONFIG["num_epochs"],
train_data=train_ds,
test_data=test_ds,
model=cross_network,
)
print_stats(
rmse_list=[cross_network_rmse],
num_params=cross_network_num_params,
model_name="Cross Network",
)
deep_network_rmse, deep_network_num_params = train_and_evaluate(
learning_rate=TOY_CONFIG["learning_rate"],
epochs=TOY_CONFIG["num_epochs"],
train_data=train_ds,
test_data=test_ds,
model=deep_network,
)
print_stats(
rmse_list=[deep_network_rmse],
num_params=deep_network_num_params,
model_name="Deep Network",
)
Cross Network: RMSE = 0.0033086808398365974; #params = 16
Deep Network: RMSE = 0.03210094943642616; #params = 166401
可视化特征交互
由于我们已经知道哪些特征交叉在我们的数据中很重要,因此验证我们的模型是否确实学习了这些关键特征交互会很有趣。这可以通过可视化交叉网络中学习到的权重矩阵来完成,其中权重 Wij 表示学习到的特征 xi 和 xj 之间交互的重要性。
visualize_layer(
matrix=cross_network.weights[0].numpy(),
features=["country", "purchased_bananas", "purchased_cookbooks"],
)
<ipython-input-4-c58988d7961d>:11: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels([""] + features, rotation=45, fontsize=5)
<ipython-input-4-c58988d7961d>:12: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_yticklabels([""] + features, fontsize=5)
<Figure size 900x900 with 0 Axes>
实际示例
让我们使用 MovieLens 100K 数据集。该数据集用于训练模型,根据用户相关特征和电影相关特征预测用户的电影评分。
准备数据集
此处的 dataset 处理步骤与 basic ranking 教程中的步骤类似。让我们加载数据集,并只保留有用的列。
ratings_ds = tfds.load("movielens/100k-ratings", split="train")
ratings_ds = ratings_ds.map(
lambda x: (
{
"movie_id": int(x["movie_id"]),
"user_id": int(x["user_id"]),
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
},
x["user_rating"], # label
)
)
WARNING:absl:Variant folder /root/tensorflow_datasets/movielens/100k-ratings/0.1.1 has no dataset_info.json
Downloading and preparing dataset Unknown size (download: Unknown size, generated: Unknown size, total: Unknown size) to /root/tensorflow_datasets/movielens/100k-ratings/0.1.1...
Dl Completed...: 0 url [00:00, ? url/s]
Dl Size...: 0 MiB [00:00, ? MiB/s]
Extraction completed...: 0 file [00:00, ? file/s]
Generating splits...: 0%| | 0/1 [00:00<?, ? splits/s]
Generating train examples...: 0 examples [00:00, ? examples/s]
Shuffling /root/tensorflow_datasets/movielens/100k-ratings/incomplete.3VSR4M_0.1.1/movielens-train.tfrecord*..…
Dataset movielens downloaded and prepared to /root/tensorflow_datasets/movielens/100k-ratings/0.1.1. Subsequent calls will reuse this data.
对于每个特征,让我们获取唯一值的列表,即词汇表,以便我们可以将其用于嵌入层。
vocabularies = {}
for feature_name in MOVIELENS_CONFIG["int_features"] + MOVIELENS_CONFIG["str_features"]:
vocabulary = ratings_ds.batch(10_000).map(lambda x, y: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocabulary)))
我们需要做的一件事是使用 keras.layers.StringLookup 和 keras.layers.IntegerLookup 将所有特征转换为索引,然后可以将其馈送到嵌入层。
lookup_layers = {}
lookup_layers.update(
{
feature: keras.layers.IntegerLookup(vocabulary=vocabularies[feature])
for feature in MOVIELENS_CONFIG["int_features"]
}
)
lookup_layers.update(
{
feature: keras.layers.StringLookup(vocabulary=vocabularies[feature])
for feature in MOVIELENS_CONFIG["str_features"]
}
)
ratings_ds = ratings_ds.map(
lambda x, y: (
{
feature_name: lookup_layers[feature_name](x[feature_name])
for feature_name in vocabularies
},
y,
)
)
我们将数据拆分为训练集和测试集。我们还使用 cache() 和 prefetch() 以获得更好的性能。
ratings_ds = ratings_ds.shuffle(100_000)
train_ds = (
ratings_ds.take(80_000)
.batch(MOVIELENS_CONFIG["batch_size"])
.cache()
.prefetch(tf.data.AUTOTUNE)
)
test_ds = (
ratings_ds.skip(80_000)
.batch(MOVIELENS_CONFIG["batch_size"])
.take(20_000)
.cache()
.prefetch(tf.data.AUTOTUNE)
)
构建模型
模型将包含嵌入层,然后是交叉和/或前馈层。
class DCN(keras.Model):
def __init__(
self,
dense_num_units_lst,
embedding_dim=MOVIELENS_CONFIG["embedding_dim"],
use_cross_layer=False,
projection_dim=None,
**kwargs,
):
super().__init__(**kwargs)
# Layers.
self.embedding_layers = []
for feature_name, vocabulary in vocabularies.items():
self.embedding_layers.append(
keras.layers.Embedding(
input_dim=len(vocabulary) + 1,
output_dim=embedding_dim,
)
)
if use_cross_layer:
self.cross_layer = keras_rs.layers.FeatureCross(
projection_dim=projection_dim
)
self.dense_layers = []
for num_units in dense_num_units_lst:
self.dense_layers.append(keras.layers.Dense(num_units, activation="relu"))
self.output_layer = keras.layers.Dense(1)
# Attributes.
self.dense_num_units_lst = dense_num_units_lst
self.embedding_dim = embedding_dim
self.use_cross_layer = use_cross_layer
self.projection_dim = projection_dim
def call(self, inputs):
embeddings = []
for feature_name, embedding_layer in zip(vocabularies, self.embedding_layers):
embeddings.append(embedding_layer(inputs[feature_name]))
x = keras.ops.concatenate(embeddings, axis=1)
if self.use_cross_layer:
x = self.cross_layer(x)
for dense_layer in self.dense_layers:
x = dense_layer(x)
x = self.output_layer(x)
return x
我们有三个模型——一个深度交叉网络,一个具有低秩矩阵的优化深度交叉网络(以降低训练和部署成本),以及一个没有交叉层的正常深度网络。深度交叉网络是一个堆叠的 DCN 模型,即输入被馈送到交叉层,然后是前馈层。我们将每个模型运行 10 次,并报告 RMSE 的平均值/标准差。
cross_network_rmse_list = []
opt_cross_network_rmse_list = []
deep_network_rmse_list = []
for _ in range(20):
cross_network = DCN(
dense_num_units_lst=MOVIELENS_CONFIG["dcn_num_units"],
embedding_dim=MOVIELENS_CONFIG["embedding_dim"],
use_cross_layer=True,
)
rmse, cross_network_num_params = train_and_evaluate(
learning_rate=MOVIELENS_CONFIG["learning_rate"],
epochs=MOVIELENS_CONFIG["num_epochs"],
train_data=train_ds,
test_data=test_ds,
model=cross_network,
)
cross_network_rmse_list.append(rmse)
opt_cross_network = DCN(
dense_num_units_lst=MOVIELENS_CONFIG["dcn_num_units"],
embedding_dim=MOVIELENS_CONFIG["embedding_dim"],
use_cross_layer=True,
projection_dim=MOVIELENS_CONFIG["projection_dim"],
)
rmse, opt_cross_network_num_params = train_and_evaluate(
learning_rate=MOVIELENS_CONFIG["learning_rate"],
epochs=MOVIELENS_CONFIG["num_epochs"],
train_data=train_ds,
test_data=test_ds,
model=opt_cross_network,
)
opt_cross_network_rmse_list.append(rmse)
deep_network = DCN(dense_num_units_lst=MOVIELENS_CONFIG["deep_net_num_units"])
rmse, deep_network_num_params = train_and_evaluate(
learning_rate=MOVIELENS_CONFIG["learning_rate"],
epochs=MOVIELENS_CONFIG["num_epochs"],
train_data=train_ds,
test_data=test_ds,
model=deep_network,
)
deep_network_rmse_list.append(rmse)
print_stats(
rmse_list=cross_network_rmse_list,
num_params=cross_network_num_params,
model_name="Cross Network",
)
print_stats(
rmse_list=opt_cross_network_rmse_list,
num_params=opt_cross_network_num_params,
model_name="Optimised Cross Network",
)
print_stats(
rmse_list=deep_network_rmse_list,
num_params=deep_network_num_params,
model_name="Deep Network",
)
Cross Network: RMSE = 0.9135891020298004 ± 0.0030034825614508568; #params = 76657
Optimised Cross Network: RMSE = 0.9156497985124588 ± 0.001790475212077632; #params = 75121
Deep Network: RMSE = 0.9173523932695389 ± 0.005951893245769413; #params = 111361
DCN 的性能略优于较大的带 ReLU 层的 DNN,显示出卓越的性能。此外,低秩 DCN 有效地减少了参数数量,而没有牺牲准确性。
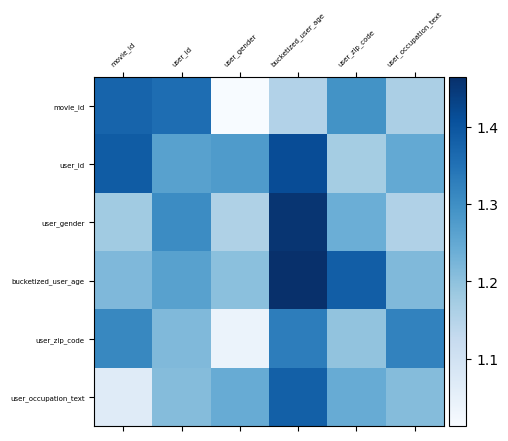
可视化特征交互
就像我们在玩具示例中所做的那样,我们将绘制交叉层的权重矩阵,以查看哪些特征交叉很重要。在前面的示例中,第 i 个和第 j 个特征之间交互的重要性由权重矩阵的 (i, j)-th 元素捕获。
在这种情况下,特征嵌入的大小为 32,而不是 1。因此,特征交互的重要性由权重矩阵的 (i, j)-th 块表示,其维度为 32 x 32。为了量化这些交互的重要性,我们使用每个块的 Frobenius 范数。值越大表示重要性越高。
features = list(vocabularies.keys())
mat = cross_network.weights[len(features)].numpy()
embedding_dim = MOVIELENS_CONFIG["embedding_dim"]
block_norm = np.zeros([len(features), len(features)])
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[
i * embedding_dim : (i + 1) * embedding_dim,
j * embedding_dim : (j + 1) * embedding_dim,
]
block_norm[i, j] = np.linalg.norm(block, ord="fro")
visualize_layer(
matrix=block_norm,
features=features,
)
<ipython-input-4-c58988d7961d>:11: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_xticklabels([""] + features, rotation=45, fontsize=5)
<ipython-input-4-c58988d7961d>:12: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
ax.set_yticklabels([""] + features, fontsize=5)
<Figure size 900x900 with 0 Axes>
这样我们就完成了!