无
电影推荐的协同过滤
作者: Siddhartha Banerjee
创建日期 2020/05/24
最后修改日期 2020/05/24
描述: 使用在 Movielens 数据集上训练的模型来推荐电影。

简介
本示例使用 Movielens 数据集 来演示 协同过滤,为用户推荐电影。MovieLens 评分数据集列出了用户对电影的评分。我们的目标是能够预测用户尚未观看的电影的评分。然后可以将评分预测最高的电影推荐给用户。
模型步骤如下:
- 通过嵌入矩阵将用户 ID 映射到“用户向量”
- 通过嵌入矩阵将电影 ID 映射到“电影向量”
- 计算用户向量和电影向量之间的点积,以获得用户与电影的匹配得分(预测评分)。
- 使用所有已知的用户-电影对通过梯度下降训练嵌入。
参考文献
import pandas as pd
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
from zipfile import ZipFile
import keras
from keras import layers
from keras import ops
首先,加载数据并进行预处理
# Download the actual data from http://files.grouplens.org/datasets/movielens/ml-latest-small.zip"
# Use the ratings.csv file
movielens_data_file_url = (
"http://files.grouplens.org/datasets/movielens/ml-latest-small.zip"
)
movielens_zipped_file = keras.utils.get_file(
"ml-latest-small.zip", movielens_data_file_url, extract=False
)
keras_datasets_path = Path(movielens_zipped_file).parents[0]
movielens_dir = keras_datasets_path / "ml-latest-small"
# Only extract the data the first time the script is run.
if not movielens_dir.exists():
with ZipFile(movielens_zipped_file, "r") as zip:
# Extract files
print("Extracting all the files now...")
zip.extractall(path=keras_datasets_path)
print("Done!")
ratings_file = movielens_dir / "ratings.csv"
df = pd.read_csv(ratings_file)
Downloading data from http://files.grouplens.org/datasets/movielens/ml-latest-small.zip
978202/978202 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
Extracting all the files now...
Done!
首先,需要进行一些预处理,将用户和电影编码为整数索引。
user_ids = df["userId"].unique().tolist()
user2user_encoded = {x: i for i, x in enumerate(user_ids)}
userencoded2user = {i: x for i, x in enumerate(user_ids)}
movie_ids = df["movieId"].unique().tolist()
movie2movie_encoded = {x: i for i, x in enumerate(movie_ids)}
movie_encoded2movie = {i: x for i, x in enumerate(movie_ids)}
df["user"] = df["userId"].map(user2user_encoded)
df["movie"] = df["movieId"].map(movie2movie_encoded)
num_users = len(user2user_encoded)
num_movies = len(movie_encoded2movie)
df["rating"] = df["rating"].values.astype(np.float32)
# min and max ratings will be used to normalize the ratings later
min_rating = min(df["rating"])
max_rating = max(df["rating"])
print(
"Number of users: {}, Number of Movies: {}, Min rating: {}, Max rating: {}".format(
num_users, num_movies, min_rating, max_rating
)
)
Number of users: 610, Number of Movies: 9724, Min rating: 0.5, Max rating: 5.0
准备训练和验证数据
df = df.sample(frac=1, random_state=42)
x = df[["user", "movie"]].values
# Normalize the targets between 0 and 1. Makes it easy to train.
y = df["rating"].apply(lambda x: (x - min_rating) / (max_rating - min_rating)).values
# Assuming training on 90% of the data and validating on 10%.
train_indices = int(0.9 * df.shape[0])
x_train, x_val, y_train, y_val = (
x[:train_indices],
x[train_indices:],
y[:train_indices],
y[train_indices:],
)
创建模型
我们将用户和电影都嵌入到 50 维向量中。
模型通过点积计算用户和电影嵌入之间的匹配得分,并添加每个电影和每个用户的偏差。匹配得分通过 sigmoid 函数缩放到 [0, 1] 区间(因为我们的评分已归一化到此范围)。
EMBEDDING_SIZE = 50
class RecommenderNet(keras.Model):
def __init__(self, num_users, num_movies, embedding_size, **kwargs):
super().__init__(**kwargs)
self.num_users = num_users
self.num_movies = num_movies
self.embedding_size = embedding_size
self.user_embedding = layers.Embedding(
num_users,
embedding_size,
embeddings_initializer="he_normal",
embeddings_regularizer=keras.regularizers.l2(1e-6),
)
self.user_bias = layers.Embedding(num_users, 1)
self.movie_embedding = layers.Embedding(
num_movies,
embedding_size,
embeddings_initializer="he_normal",
embeddings_regularizer=keras.regularizers.l2(1e-6),
)
self.movie_bias = layers.Embedding(num_movies, 1)
def call(self, inputs):
user_vector = self.user_embedding(inputs[:, 0])
user_bias = self.user_bias(inputs[:, 0])
movie_vector = self.movie_embedding(inputs[:, 1])
movie_bias = self.movie_bias(inputs[:, 1])
dot_user_movie = ops.tensordot(user_vector, movie_vector, 2)
# Add all the components (including bias)
x = dot_user_movie + user_bias + movie_bias
# The sigmoid activation forces the rating to between 0 and 1
return ops.nn.sigmoid(x)
model = RecommenderNet(num_users, num_movies, EMBEDDING_SIZE)
model.compile(
loss=keras.losses.BinaryCrossentropy(),
optimizer=keras.optimizers.Adam(learning_rate=0.001),
)
根据数据划分训练模型
history = model.fit(
x=x_train,
y=y_train,
batch_size=64,
epochs=5,
verbose=1,
validation_data=(x_val, y_val),
)
Epoch 1/5
1418/1418 ━━━━━━━━━━━━━━━━━━━━ 2s 1ms/step - loss: 0.6591 - val_loss: 0.6201
Epoch 2/5
1418/1418 ━━━━━━━━━━━━━━━━━━━━ 1s 894us/step - loss: 0.6159 - val_loss: 0.6191
Epoch 3/5
1418/1418 ━━━━━━━━━━━━━━━━━━━━ 1s 977us/step - loss: 0.6093 - val_loss: 0.6138
Epoch 4/5
1418/1418 ━━━━━━━━━━━━━━━━━━━━ 1s 865us/step - loss: 0.6100 - val_loss: 0.6123
Epoch 5/5
1418/1418 ━━━━━━━━━━━━━━━━━━━━ 1s 854us/step - loss: 0.6072 - val_loss: 0.6121
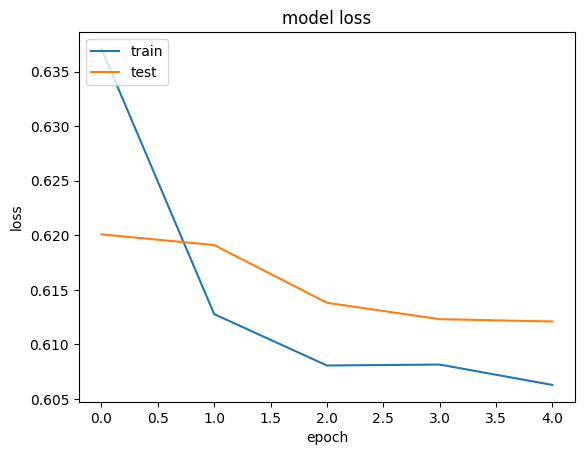
绘制训练和验证损失
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
向用户展示前 10 部推荐电影
movie_df = pd.read_csv(movielens_dir / "movies.csv")
# Let us get a user and see the top recommendations.
user_id = df.userId.sample(1).iloc[0]
movies_watched_by_user = df[df.userId == user_id]
movies_not_watched = movie_df[
~movie_df["movieId"].isin(movies_watched_by_user.movieId.values)
]["movieId"]
movies_not_watched = list(
set(movies_not_watched).intersection(set(movie2movie_encoded.keys()))
)
movies_not_watched = [[movie2movie_encoded.get(x)] for x in movies_not_watched]
user_encoder = user2user_encoded.get(user_id)
user_movie_array = np.hstack(
([[user_encoder]] * len(movies_not_watched), movies_not_watched)
)
ratings = model.predict(user_movie_array).flatten()
top_ratings_indices = ratings.argsort()[-10:][::-1]
recommended_movie_ids = [
movie_encoded2movie.get(movies_not_watched[x][0]) for x in top_ratings_indices
]
print("Showing recommendations for user: {}".format(user_id))
print("====" * 9)
print("Movies with high ratings from user")
print("----" * 8)
top_movies_user = (
movies_watched_by_user.sort_values(by="rating", ascending=False)
.head(5)
.movieId.values
)
movie_df_rows = movie_df[movie_df["movieId"].isin(top_movies_user)]
for row in movie_df_rows.itertuples():
print(row.title, ":", row.genres)
print("----" * 8)
print("Top 10 movie recommendations")
print("----" * 8)
recommended_movies = movie_df[movie_df["movieId"].isin(recommended_movie_ids)]
for row in recommended_movies.itertuples():
print(row.title, ":", row.genres)
272/272 ━━━━━━━━━━━━━━━━━━━━ 0s 714us/step
Showing recommendations for user: 249
====================================
Movies with high ratings from user
--------------------------------
Fight Club (1999) : Action|Crime|Drama|Thriller
Serenity (2005) : Action|Adventure|Sci-Fi
Departed, The (2006) : Crime|Drama|Thriller
Prisoners (2013) : Drama|Mystery|Thriller
Arrival (2016) : Sci-Fi
--------------------------------
Top 10 movie recommendations
--------------------------------
In the Name of the Father (1993) : Drama
Monty Python and the Holy Grail (1975) : Adventure|Comedy|Fantasy
Princess Bride, The (1987) : Action|Adventure|Comedy|Fantasy|Romance
Lawrence of Arabia (1962) : Adventure|Drama|War
Apocalypse Now (1979) : Action|Drama|War
Full Metal Jacket (1987) : Drama|War
Amadeus (1984) : Drama
Glory (1989) : Drama|War
Chinatown (1974) : Crime|Film-Noir|Mystery|Thriller
City of God (Cidade de Deus) (2002) : Action|Adventure|Crime|Drama|Thriller