使用决策森林和预训练的嵌入进行文本分类
作者: Gitesh Chawda
创建日期 09/05/2022
最后修改日期 09/05/2022
描述: 使用 Tensorflow Decision Forests 进行文本分类。

简介
TensorFlow Decision Forests (TF-DF) 是一系列最先进的决策森林模型算法,与 Keras API 兼容。该模块包括随机森林、梯度提升树和 CART,可用于回归、分类和排序任务。
在此示例中,我们将使用梯度提升树和预训练嵌入来对灾难相关的推文进行分类。
另请参阅
使用以下命令安装 Tensorflow Decision Forest:pip install tensorflow_decision_forests
导入
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow import keras
import tensorflow_hub as hub
from tensorflow.keras import layers
import tensorflow_decision_forests as tfdf
import matplotlib.pyplot as plt
获取数据
数据集可在 Kaggle 上找到。
数据集描述
文件
- train.csv:训练集
列
- id:每条推文的唯一标识符
- text:推文内容
- location:发送推文的位置(可能为空)
- keyword:推文中的特定关键词(可能为空)
- target:仅在 train.csv 中,此列表示推文是否与真实灾难相关(1)或无关(0)
# Turn .csv files into pandas DataFrame's
df = pd.read_csv(
"https://raw.githubusercontent.com/IMvision12/Tweets-Classification-NLP/main/train.csv"
)
print(df.head())
id keyword location text \
0 1 NaN NaN Our Deeds are the Reason of this #earthquake M...
1 4 NaN NaN Forest fire near La Ronge Sask. Canada
2 5 NaN NaN All residents asked to 'shelter in place' are ...
3 6 NaN NaN 13,000 people receive #wildfires evacuation or...
4 7 NaN NaN Just got sent this photo from Ruby #Alaska as ...
target
0 1
1 1
2 1
3 1
4 1
该数据集包含 7613 个样本,分为 5 列。
print(f"Training dataset shape: {df.shape}")
Training dataset shape: (7613, 5)
打乱顺序并删除不必要的列
df_shuffled = df.sample(frac=1, random_state=42)
# Dropping id, keyword and location columns as these columns consists of mostly nan values
# we will be using only text and target columns
df_shuffled.drop(["id", "keyword", "location"], axis=1, inplace=True)
df_shuffled.reset_index(inplace=True, drop=True)
print(df_shuffled.head())
text target
0 So you have a new weapon that can cause un-ima... 1
1 The f$&@ing things I do for #GISHWHES Just... 0
2 DT @georgegalloway: RT @Galloway4Mayor: ÛÏThe... 1
3 Aftershock back to school kick off was great. ... 0
4 in response to trauma Children of Addicts deve... 0
打印打乱顺序后的数据帧信息
print(df_shuffled.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7613 entries, 0 to 7612
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 text 7613 non-null object
1 target 7613 non-null int64
dtypes: int64(1), object(1)
memory usage: 119.1+ KB
None
"灾难"和"非灾难"推文的总数
print(
"Total Number of disaster and non-disaster tweets: "
f"{df_shuffled.target.value_counts()}"
)
Total Number of disaster and non-disaster tweets: 0 4342
1 3271
Name: target, dtype: int64
让我们预览几个样本
for index, example in df_shuffled[:5].iterrows():
print(f"Example #{index}")
print(f"\tTarget : {example['target']}")
print(f"\tText : {example['text']}")
Example #0
Target : 1
Text : So you have a new weapon that can cause un-imaginable destruction.
Example #1
Target : 0
Text : The f$&@ing things I do for #GISHWHES Just got soaked in a deluge going for pads and tampons. Thx @mishacollins @/@
Example #2
Target : 1
Text : DT @georgegalloway: RT @Galloway4Mayor: ÛÏThe CoL police can catch a pickpocket in Liverpool Stree... https://#/vXIn1gOq4Q
Example #3
Target : 0
Text : Aftershock back to school kick off was great. I want to thank everyone for making it possible. What a great night.
Example #4
Target : 0
Text : in response to trauma Children of Addicts develop a defensive self - one that decreases vulnerability. (3
将数据集拆分为训练集和测试集
test_df = df_shuffled.sample(frac=0.1, random_state=42)
train_df = df_shuffled.drop(test_df.index)
print(f"Using {len(train_df)} samples for training and {len(test_df)} for validation")
Using 6852 samples for training and 761 for validation
训练数据中"灾难"和"非灾难"推文的总数
print(train_df["target"].value_counts())
0 3929
1 2923
Name: target, dtype: int64
测试数据中"灾难"和"非灾难"推文的总数
print(test_df["target"].value_counts())
0 413
1 348
Name: target, dtype: int64
将数据转换为 tf.data.Dataset
def create_dataset(dataframe):
dataset = tf.data.Dataset.from_tensor_slices(
(dataframe["text"].to_numpy(), dataframe["target"].to_numpy())
)
dataset = dataset.batch(100)
dataset = dataset.prefetch(tf.data.AUTOTUNE)
return dataset
train_ds = create_dataset(train_df)
test_ds = create_dataset(test_df)
下载预训练嵌入
通用句子编码器 (Universal Sentence Encoder) 将文本编码为高维向量,可用于文本分类、语义相似度、聚类和其他自然语言任务。它们在各种数据源和任务上进行了训练。其输入是可变长度的英文文本,输出是 512 维向量。
要了解有关这些预训练嵌入的更多信息,请参阅 通用句子编码器。
sentence_encoder_layer = hub.KerasLayer(
"https://tfhub.dev/google/universal-sentence-encoder/4"
)
创建我们的模型
我们创建两个模型。在第一个模型(model_1)中,原始文本将首先通过预训练嵌入进行编码,然后传递给梯度提升树模型进行分类。在第二个模型(model_2)中,原始文本将直接传递给梯度提升树模型。
构建 model_1
inputs = layers.Input(shape=(), dtype=tf.string)
outputs = sentence_encoder_layer(inputs)
preprocessor = keras.Model(inputs=inputs, outputs=outputs)
model_1 = tfdf.keras.GradientBoostedTreesModel(preprocessing=preprocessor)
Use /tmp/tmpsp7fmsyk as temporary training directory
构建 model_2
model_2 = tfdf.keras.GradientBoostedTreesModel()
Use /tmp/tmpl0zj3vw0 as temporary training directory
训练模型
我们通过传递 `Accuracy`、`Recall`、`Precision` 和 `AUC` 指标来编译模型。在损失方面,TF-DF 会自动检测任务(分类或回归)的最佳损失。它会打印在模型摘要中。
此外,由于它们是批处理模型而不是小批量梯度下降模型,因此 TF-DF 模型不需要验证数据集来监控过拟合或提前停止训练。某些算法不需要验证数据集(例如,随机森林),而另一些则需要(例如,梯度提升树)。如果需要验证数据集,它将自动从训练数据集中提取。
# Compiling model_1
model_1.compile(metrics=["Accuracy", "Recall", "Precision", "AUC"])
# Here we do not specify epochs as, TF-DF trains exactly one epoch of the dataset
model_1.fit(train_ds)
# Compiling model_2
model_2.compile(metrics=["Accuracy", "Recall", "Precision", "AUC"])
# Here we do not specify epochs as, TF-DF trains exactly one epoch of the dataset
model_2.fit(train_ds)
Reading training dataset...
Training dataset read in 0:00:06.473683. Found 6852 examples.
Training model...
Model trained in 0:00:41.461477
Compiling model...
Model compiled.
Reading training dataset...
Training dataset read in 0:00:00.087930. Found 6852 examples.
Training model...
Model trained in 0:00:00.367492
Compiling model...
Model compiled.
<keras.callbacks.History at 0x7fe09ded1b40>
打印 model_1 的训练日志
logs_1 = model_1.make_inspector().training_logs()
print(logs_1)
打印 model_2 的训练日志
logs_2 = model_2.make_inspector().training_logs()
print(logs_2)
model.summary() 方法会打印出关于您的决策树模型的各种信息,包括模型类型、任务、输入特征和特征重要性。
print("model_1 summary: ")
print(model_1.summary())
print()
print("model_2 summary: ")
print(model_2.summary())
model_1 summary:
Model: "gradient_boosted_trees_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
model (Functional) (None, 512) 256797824
=================================================================
Total params: 256,797,825
Trainable params: 0
Non-trainable params: 256,797,825
_________________________________________________________________
Type: "GRADIENT_BOOSTED_TREES"
Task: CLASSIFICATION
Label: "__LABEL"
No weights
Loss: BINOMIAL_LOG_LIKELIHOOD
Validation loss value: 0.806777
Number of trees per iteration: 1
Node format: NOT_SET
Number of trees: 137
Total number of nodes: 6671
Number of nodes by tree:
Count: 137 Average: 48.6934 StdDev: 9.91023
Min: 21 Max: 63 Ignored: 0
----------------------------------------------
[ 21, 23) 1 0.73% 0.73%
[ 23, 25) 1 0.73% 1.46%
[ 25, 27) 0 0.00% 1.46%
[ 27, 29) 1 0.73% 2.19%
[ 29, 31) 3 2.19% 4.38% #
[ 31, 33) 3 2.19% 6.57% #
[ 33, 36) 9 6.57% 13.14% ####
[ 36, 38) 4 2.92% 16.06% ##
[ 38, 40) 4 2.92% 18.98% ##
[ 40, 42) 8 5.84% 24.82% ####
[ 42, 44) 8 5.84% 30.66% ####
[ 44, 46) 9 6.57% 37.23% ####
[ 46, 48) 7 5.11% 42.34% ###
[ 48, 51) 10 7.30% 49.64% #####
[ 51, 53) 13 9.49% 59.12% ######
[ 53, 55) 10 7.30% 66.42% #####
[ 55, 57) 10 7.30% 73.72% #####
[ 57, 59) 6 4.38% 78.10% ###
[ 59, 61) 8 5.84% 83.94% ####
[ 61, 63] 22 16.06% 100.00% ##########
Depth by leafs:
Count: 3404 Average: 4.81052 StdDev: 0.557183
Min: 1 Max: 5 Ignored: 0
----------------------------------------------
[ 1, 2) 6 0.18% 0.18%
[ 2, 3) 38 1.12% 1.29%
[ 3, 4) 117 3.44% 4.73%
[ 4, 5) 273 8.02% 12.75% #
[ 5, 5] 2970 87.25% 100.00% ##########
Number of training obs by leaf:
Count: 3404 Average: 248.806 StdDev: 517.403
Min: 5 Max: 4709 Ignored: 0
----------------------------------------------
[ 5, 240) 2615 76.82% 76.82% ##########
[ 240, 475) 243 7.14% 83.96% #
[ 475, 710) 162 4.76% 88.72% #
[ 710, 946) 104 3.06% 91.77%
[ 946, 1181) 80 2.35% 94.12%
[ 1181, 1416) 48 1.41% 95.53%
[ 1416, 1651) 44 1.29% 96.83%
[ 1651, 1887) 27 0.79% 97.62%
[ 1887, 2122) 18 0.53% 98.15%
[ 2122, 2357) 19 0.56% 98.71%
[ 2357, 2592) 10 0.29% 99.00%
[ 2592, 2828) 6 0.18% 99.18%
[ 2828, 3063) 8 0.24% 99.41%
[ 3063, 3298) 7 0.21% 99.62%
[ 3298, 3533) 3 0.09% 99.71%
[ 3533, 3769) 5 0.15% 99.85%
[ 3769, 4004) 2 0.06% 99.91%
[ 4004, 4239) 1 0.03% 99.94%
[ 4239, 4474) 1 0.03% 99.97%
[ 4474, 4709] 1 0.03% 100.00%
Condition type in nodes:
3267 : HigherCondition
Condition type in nodes with depth <= 0:
137 : HigherCondition
Condition type in nodes with depth <= 1:
405 : HigherCondition
Condition type in nodes with depth <= 2:
903 : HigherCondition
Condition type in nodes with depth <= 3:
1782 : HigherCondition
Condition type in nodes with depth <= 5:
3267 : HigherCondition
None
model_2 summary:
Model: "gradient_boosted_trees_model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
=================================================================
Total params: 1
Trainable params: 0
Non-trainable params: 1
_________________________________________________________________
Type: "GRADIENT_BOOSTED_TREES"
Task: CLASSIFICATION
Label: "__LABEL"
Input Features (1):
data:0
No weights
Variable Importance: MEAN_MIN_DEPTH:
1. "__LABEL" 2.250000 ################
2. "data:0" 0.000000
Variable Importance: NUM_AS_ROOT:
1. "data:0" 117.000000
Variable Importance: NUM_NODES:
1. "data:0" 351.000000
Variable Importance: SUM_SCORE:
1. "data:0" 32.035971
Loss: BINOMIAL_LOG_LIKELIHOOD
Validation loss value: 1.36429
Number of trees per iteration: 1
Node format: NOT_SET
Number of trees: 117
Total number of nodes: 819
Number of nodes by tree:
Count: 117 Average: 7 StdDev: 0
Min: 7 Max: 7 Ignored: 0
----------------------------------------------
[ 7, 7] 117 100.00% 100.00% ##########
Depth by leafs:
Count: 468 Average: 2.25 StdDev: 0.829156
Min: 1 Max: 3 Ignored: 0
----------------------------------------------
[ 1, 2) 117 25.00% 25.00% #####
[ 2, 3) 117 25.00% 50.00% #####
[ 3, 3] 234 50.00% 100.00% ##########
Number of training obs by leaf:
Count: 468 Average: 1545.5 StdDev: 2660.15
Min: 5 Max: 6153 Ignored: 0
----------------------------------------------
[ 5, 312) 351 75.00% 75.00% ##########
[ 312, 619) 0 0.00% 75.00%
[ 619, 927) 0 0.00% 75.00%
[ 927, 1234) 0 0.00% 75.00%
[ 1234, 1542) 0 0.00% 75.00%
[ 1542, 1849) 0 0.00% 75.00%
[ 1849, 2157) 0 0.00% 75.00%
[ 2157, 2464) 0 0.00% 75.00%
[ 2464, 2772) 0 0.00% 75.00%
[ 2772, 3079) 0 0.00% 75.00%
[ 3079, 3386) 0 0.00% 75.00%
[ 3386, 3694) 0 0.00% 75.00%
[ 3694, 4001) 0 0.00% 75.00%
[ 4001, 4309) 0 0.00% 75.00%
[ 4309, 4616) 0 0.00% 75.00%
[ 4616, 4924) 0 0.00% 75.00%
[ 4924, 5231) 0 0.00% 75.00%
[ 5231, 5539) 0 0.00% 75.00%
[ 5539, 5846) 0 0.00% 75.00%
[ 5846, 6153] 117 25.00% 100.00% ###
Attribute in nodes:
351 : data:0 [CATEGORICAL]
Attribute in nodes with depth <= 0:
117 : data:0 [CATEGORICAL]
Attribute in nodes with depth <= 1:
234 : data:0 [CATEGORICAL]
Attribute in nodes with depth <= 2:
351 : data:0 [CATEGORICAL]
Attribute in nodes with depth <= 3:
351 : data:0 [CATEGORICAL]
Attribute in nodes with depth <= 5:
351 : data:0 [CATEGORICAL]
Condition type in nodes:
351 : ContainsBitmapCondition
Condition type in nodes with depth <= 0:
117 : ContainsBitmapCondition
Condition type in nodes with depth <= 1:
234 : ContainsBitmapCondition
Condition type in nodes with depth <= 2:
351 : ContainsBitmapCondition
Condition type in nodes with depth <= 3:
351 : ContainsBitmapCondition
Condition type in nodes with depth <= 5:
351 : ContainsBitmapCondition
None
绘制训练指标
def plot_curve(logs):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot([log.num_trees for log in logs], [log.evaluation.accuracy for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Accuracy")
plt.subplot(1, 2, 2)
plt.plot([log.num_trees for log in logs], [log.evaluation.loss for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Loss")
plt.show()
plot_curve(logs_1)
plot_curve(logs_2)
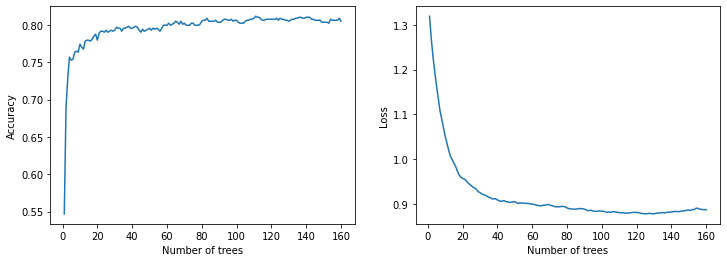
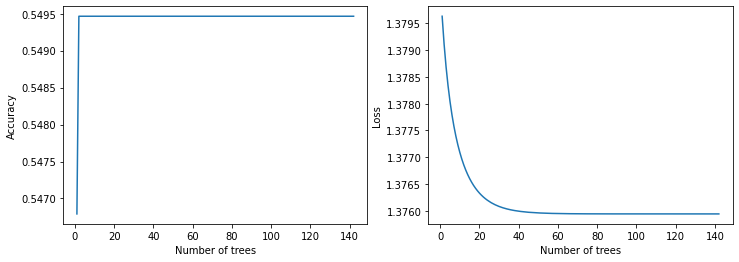
在测试数据上进行评估
results = model_1.evaluate(test_ds, return_dict=True, verbose=0)
print("model_1 Evaluation: \n")
for name, value in results.items():
print(f"{name}: {value:.4f}")
results = model_2.evaluate(test_ds, return_dict=True, verbose=0)
print("model_2 Evaluation: \n")
for name, value in results.items():
print(f"{name}: {value:.4f}")
model_1 Evaluation:
loss: 0.0000
Accuracy: 0.8160
recall: 0.7241
precision: 0.8514
auc: 0.8700
model_2 Evaluation:
loss: 0.0000
Accuracy: 0.5440
recall: 0.0029
precision: 1.0000
auc: 0.5026
在验证数据上进行预测
test_df.reset_index(inplace=True, drop=True)
for index, row in test_df.iterrows():
text = tf.expand_dims(row["text"], axis=0)
preds = model_1.predict_step(text)
preds = tf.squeeze(tf.round(preds))
print(f"Text: {row['text']}")
print(f"Prediction: {int(preds)}")
print(f"Ground Truth : {row['target']}")
if index == 10:
break
Text: DFR EP016 Monthly Meltdown - On Dnbheaven 2015.08.06 https://#/EjKRf8N8A8 #Drum and Bass #heavy #nasty https://#/SPHWE6wFI5
Prediction: 0
Ground Truth : 0
Text: FedEx no longer to transport bioterror germs in wake of anthrax lab mishaps https://#/qZQc8WWwcN via @usatoday
Prediction: 1
Ground Truth : 0
Text: Gunmen kill four in El Salvador bus attack: Suspected Salvadoran gang members killed four people and wounded s... https://#/CNtwB6ScZj
Prediction: 1
Ground Truth : 1
Text: @camilacabello97 Internally and externally screaming
Prediction: 0
Ground Truth : 1
Text: Radiation emergency #preparedness starts with knowing to: get inside stay inside and stay tuned https://#/RFFPqBAz2F via @CDCgov
Prediction: 1
Ground Truth : 1
Text: Investigators rule catastrophic structural failure resulted in 2014 Virg.. Related Articles: https://#/Cy1LFeNyV8
Prediction: 1
Ground Truth : 1
Text: How the West was burned: Thousands of wildfires ablaze in #California alone https://#/iCSjGZ9tE1 #climate #energy https://#/9FxmN0l0Bd
Prediction: 1
Ground Truth : 1
Text: Map: Typhoon Soudelor's predicted path as it approaches Taiwan; expected to make landfall over southern China by SÛ_ https://#/JDVSGVhlIs
Prediction: 1
Ground Truth : 1
Text: Ûª93 blasts accused Yeda Yakub dies in Karachi of heart attack https://#/mfKqyxd8XG #Mumbai
Prediction: 1
Ground Truth : 1
Text: My ears are bleeding https://#/k5KnNwugwT
Prediction: 0
Ground Truth : 0
Text: @RedCoatJackpot *As it was typical for them their bullets collided and none managed to reach their targets; such was the ''curse'' of a --
Prediction: 0
Ground Truth : 0
结论
TensorFlow Decision Forests 包提供了强大的模型,尤其适用于结构化数据。在我们的实验中,带有预训练嵌入的梯度提升树模型达到了 81.6% 的测试准确率,而普通的梯度提升树模型准确率为 54.4%。