使用 LoRA 对 GPT-2 进行参数高效微调
作者: Abheesht Sharma, Matthew Watson
创建日期 2023/05/27
最后修改日期 2023/05/27
描述: 使用 KerasHub 微调 GPT-2 LLM 和 LoRA。

简介
大型语言模型 (LLM) 已被证明在各种 NLP 任务中非常有效。LLM 首先在大型文本语料库上以自监督方式进行预训练。预训练有助于 LLM 学习通用知识,例如单词之间的统计关系。然后,LLM 可以针对感兴趣的下游任务(例如情感分析)进行微调。
然而,LLM 的尺寸非常大,我们在微调时不需要训练模型中的所有参数,尤其是在模型微调的数据集相对较小的情况下。换句话说,LLM 对于微调来说是过度参数化的。这就是 低秩适配 (LoRA) 的用武之地;它显著减少了可训练参数的数量。这会降低训练时间和 GPU 内存使用量,同时保持输出的质量。
在此示例中,我们将从技术角度解释 LoRA,展示技术解释如何转化为代码, hack KerasHub 的 GPT-2 模型,并使用 LoRA 在下一个词预测任务上对其进行微调。我们将从生成文本的质量、训练时间和 GPU 内存使用量方面比较 LoRA GPT-2 和完全微调的 GPT-2。
注意:此示例仅为方便绘制内存使用情况而运行 TensorFlow 后端,以使用 tf.config.experimental.get_memory_info API。除了内存使用情况回调外,此示例将在 jax 和 torch 后端上运行。
设置
在开始实现流水线之前,让我们安装并导入所有需要的库。我们将使用 KerasHub 库。
其次,让我们启用混合精度训练。这将帮助我们减少训练时间。
!pip install -q --upgrade keras-hub
!pip install -q --upgrade keras # Upgrade to Keras 3.
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras_hub
import keras
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
import time
keras.mixed_precision.set_global_policy("mixed_float16")
我们还来定义超参数。
# General hyperparameters
BATCH_SIZE = 32
NUM_BATCHES = 500
EPOCHS = 1 # Can be set to a higher value for better results
MAX_SEQUENCE_LENGTH = 128
MAX_GENERATION_LENGTH = 200
GPT2_PRESET = "gpt2_base_en"
# LoRA-specific hyperparameters
RANK = 4
ALPHA = 32.0
数据集
让我们加载一个 Reddit 数据集。我们将在此数据集的子集上微调 GPT-2 模型和 LoRA GPT-2 模型。目标是生成风格与 Reddit 帖子相似的文本。
reddit_ds = tfds.load("reddit_tifu", split="train", as_supervised=True)
该数据集有两个字段:document 和 title。
for document, title in reddit_ds:
print(document.numpy())
print(title.numpy())
break
b"me and a friend decided to go to the beach last sunday. we loaded up and headed out. we were about half way there when i decided that i was not leaving till i had seafood. \n\nnow i'm not talking about red lobster. no friends i'm talking about a low country boil. i found the restaurant and got directions. i don't know if any of you have heard about the crab shack on tybee island but let me tell you it's worth it. \n\nwe arrived and was seated quickly. we decided to get a seafood sampler for two and split it. the waitress bought it out on separate platters for us. the amount of food was staggering. two types of crab, shrimp, mussels, crawfish, andouille sausage, red potatoes, and corn on the cob. i managed to finish it and some of my friends crawfish and mussels. it was a day to be a fat ass. we finished paid for our food and headed to the beach. \n\nfunny thing about seafood. it runs through me faster than a kenyan \n\nwe arrived and walked around a bit. it was about 45min since we arrived at the beach when i felt a rumble from the depths of my stomach. i ignored it i didn't want my stomach to ruin our fun. i pushed down the feeling and continued. about 15min later the feeling was back and stronger than before. again i ignored it and continued. 5min later it felt like a nuclear reactor had just exploded in my stomach. i started running. i yelled to my friend to hurry the fuck up. \n\nrunning in sand is extremely hard if you did not know this. we got in his car and i yelled at him to floor it. my stomach was screaming and if he didn't hurry i was gonna have this baby in his car and it wasn't gonna be pretty. after a few red lights and me screaming like a woman in labor we made it to the store. \n\ni practically tore his car door open and ran inside. i ran to the bathroom opened the door and barely got my pants down before the dam burst and a flood of shit poured from my ass. \n\ni finished up when i felt something wet on my ass. i rubbed it thinking it was back splash. no, mass was covered in the after math of me abusing the toilet. i grabbed all the paper towels i could and gave my self a whores bath right there. \n\ni sprayed the bathroom down with the air freshener and left. an elderly lady walked in quickly and closed the door. i was just about to walk away when i heard gag. instead of walking i ran. i got to the car and told him to get the hell out of there."
b'liking seafood'
我们现在将对数据集进行批处理,并仅保留 document 字段,因为我们在下一个词预测任务上微调模型。为了本示例的目的,请采用数据集的子集。
train_ds = (
reddit_ds.map(lambda document, _: document)
.batch(BATCH_SIZE)
.cache()
.prefetch(tf.data.AUTOTUNE)
)
train_ds = train_ds.take(NUM_BATCHES)
辅助函数
在开始微调模型之前,让我们定义一些辅助函数和类。
用于跟踪 GPU 内存使用情况的回调
我们将定义一个自定义回调函数来跟踪 GPU 内存使用情况。该回调函数使用 TensorFlow 的 tf.config.experimental.get_memory_info API。
在这里,我们假设我们正在使用单个 GPU,GPU:0。
class GPUMemoryCallback(keras.callbacks.Callback):
def __init__(
self,
target_batches,
print_stats=False,
**kwargs,
):
super().__init__(**kwargs)
self.target_batches = target_batches
self.print_stats = print_stats
self.memory_usage = []
self.labels = []
def _compute_memory_usage(self):
memory_stats = tf.config.experimental.get_memory_info("GPU:0")
# Convert bytes to GB and store in list.
peak_usage = round(memory_stats["peak"] / (2**30), 3)
self.memory_usage.append(peak_usage)
def on_epoch_begin(self, epoch, logs=None):
self._compute_memory_usage()
self.labels.append(f"epoch {epoch} start")
def on_train_batch_begin(self, batch, logs=None):
if batch in self.target_batches:
self._compute_memory_usage()
self.labels.append(f"batch {batch}")
def on_epoch_end(self, epoch, logs=None):
self._compute_memory_usage()
self.labels.append(f"epoch {epoch} end")
文本生成函数
这是一个用于生成文本的辅助函数。
def generate_text(model, input_text, max_length=200):
start = time.time()
output = model.generate(input_text, max_length=max_length)
print("\nOutput:")
print(output)
end = time.time()
print(f"Total Time Elapsed: {end - start:.2f}s")
定义优化器和损失
我们将使用 AdamW 优化器和交叉熵损失来训练这两个模型。
def get_optimizer_and_loss():
optimizer = keras.optimizers.AdamW(
learning_rate=5e-5,
weight_decay=0.01,
epsilon=1e-6,
global_clipnorm=1.0, # Gradient clipping.
)
# Exclude layernorm and bias terms from weight decay.
optimizer.exclude_from_weight_decay(var_names=["bias"])
optimizer.exclude_from_weight_decay(var_names=["gamma"])
optimizer.exclude_from_weight_decay(var_names=["beta"])
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
return optimizer, loss
微调 GPT-2
让我们先加载模型和预处理器。我们使用 128 的序列长度而不是 1024(默认序列长度)。这将限制我们预测长序列的能力,但可以让我们在 Colab 上快速运行此示例。
preprocessor = keras_hub.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=MAX_SEQUENCE_LENGTH,
)
gpt2_lm = keras_hub.models.GPT2CausalLM.from_preset(
"gpt2_base_en", preprocessor=preprocessor
)
gpt2_lm.summary()
Preprocessor: "gpt2_causal_lm_preprocessor"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Tokenizer (type) ┃ Vocab # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ gpt2_tokenizer (GPT2Tokenizer) │ 50,257 │ └────────────────────────────────────────────────────┴─────────────────────────────────────────────────────┘
Model: "gpt2_causal_lm"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask (InputLayer) │ (None, None) │ 0 │ - │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ token_ids (InputLayer) │ (None, None) │ 0 │ - │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ gpt2_backbone (GPT2Backbone) │ (None, None, 768) │ 124,439,808 │ padding_mask[0][0], │ │ │ │ │ token_ids[0][0] │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ token_embedding │ (None, None, 50257) │ 38,597,376 │ gpt2_backbone[0][0] │ │ (ReversibleEmbedding) │ │ │ │ └───────────────────────────────┴───────────────────────────┴─────────────┴────────────────────────────────┘
Total params: 124,439,808 (474.70 MB)
Trainable params: 124,439,808 (474.70 MB)
Non-trainable params: 0 (0.00 B)
初始化 GPU 内存跟踪器回调对象,并编译模型。我们使用 Adam 优化器和线性衰减的学习率。
gpu_memory_callback = GPUMemoryCallback(
target_batches=[5, 10, 25, 50, 100, 150, 200, 300, 400, 500],
print_stats=True,
)
optimizer, loss = get_optimizer_and_loss()
gpt2_lm.compile(
optimizer=optimizer,
loss=loss,
weighted_metrics=["accuracy"],
)
我们已准备好训练模型!
gpt2_lm.fit(train_ds, epochs=EPOCHS, callbacks=[gpu_memory_callback])
gpt2_lm_memory_usage = gpu_memory_callback.memory_usage
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1701128462.076856 38706 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
W0000 00:00:1701128462.146837 38706 graph_launch.cc:671] Fallback to op-by-op mode because memset node breaks graph update
500/500 ━━━━━━━━━━━━━━━━━━━━ 114s 128ms/step - accuracy: 0.3183 - loss: 3.3682
作为最后一步,让我们生成一些文本。我们将利用 XLA 的强大功能。第一次调用 generate() 将因 XLA 编译而变慢,但后续调用将非常快。 :)
generate_text(gpt2_lm, "I like basketball", max_length=MAX_GENERATION_LENGTH)
generate_text(gpt2_lm, "That Italian restaurant is", max_length=MAX_GENERATION_LENGTH)
Output:
I like basketball, but this one actually happened a few months ago.
i was on my way to a party in the city when i noticed a group of guys were playing basketball. one of my friends, a guy named "jenny," was playing. jenny's mom, a very nice girl, was sitting on her couch.
jenny and jenny were sitting in a circle around her, and i started to play some of my favorite basketball games. i got to the end of the circle and jenny started to run. i didn't know how jenny was doing. she ran, but it
Total Time Elapsed: 6.66s
Output:
That Italian restaurant is a bit of a mystery, because the place is closed.
so i was at my friends house and i went to grab some food, so i got the usual pizza and some chicken, but it wasn't really the pizza, so i just grabbed my friend's pizza.
i had a lot of chicken, but i was hungry, so i decided to grab a few of the other pizza's that were already in there.
i was eating the pizza with some friends and i was eating the pizza and then i got a knock on the door.
the guy in front of me is
Total Time Elapsed: 0.22s
LoRA GPT-2
在本节中,我们将讨论 LoRA 的技术细节,构建 LoRA GPT-2 模型,对其进行微调并生成文本。
LoRA 到底是什么?
LoRA 是一种用于 LLM 的参数高效微调技术。它冻结 LLM 的权重,并注入可训练的秩分解矩阵。让我们更清楚地理解这一点。
假设我们有一个 n x n 的预训练密集层(或权重矩阵)W0。我们初始化两个形状分别为 n x rank 和 rank x n 的密集层 A 和 B。rank 远小于 n。在论文中,1 到 4 之间的值已被证明效果良好。
LoRA 方程
原始方程是 output = W0x + b0,其中 x 是输入,W0 和 b0 是原始密集层(已冻结)的权重矩阵和偏差项。LoRA 方程是:output = W0x + b0 + BAx,其中 A 和 B 是秩分解矩阵。
LoRA 基于以下观点:预训练语言模型的权重更新具有较低的“内在秩”,因为预训练语言模型是过度参数化的。即使通过将 W0 的更新限制为低秩分解矩阵,也可以复制完全微调的预测性能。

可训练参数的数量
让我们做一些快速计算。假设 n 为 768,rank 为 4。W0 有 768 x 768 = 589,824 个参数,而 LoRA 层 A 和 B 加起来有 768 x 4 + 4 x 768 = 6,144 个参数。因此,对于密集层,我们从 589,824 个可训练参数减少到 6,144 个可训练参数!
为什么 LoRA 会减少内存占用?
尽管总参数数量会增加(因为我们添加了 LoRA 层),但内存占用会减少,因为可训练参数的数量减少了。让我们深入探讨一下。
模型的内存使用量可分为四部分
- 模型内存:这是存储模型权重所需的内存。LoRA 的内存会比 GPT-2 略高。
- 前向传播内存:这主要取决于批量大小、序列长度等。为了公平比较,我们对两个模型保持此值不变。
- 反向传播内存:这是存储梯度的内存。请注意,梯度仅为可训练参数计算。
- 优化器内存:这是存储优化器状态所需的内存。例如,Adam 优化器会为可训练参数存储“一阶矩向量”和“二阶矩向量”。
由于 LoRA 可训练参数数量大幅减少,因此 LoRA 的优化器内存和存储梯度所需的内存远少于 GPT-2。这就是大多数内存节省发生的地方。
为什么 LoRA 如此受欢迎?
- 减少 GPU 内存使用量;
- 训练速度更快;以及
- 无额外的推理延迟。
创建 LoRA 层
根据上面的技术描述,让我们创建一个 LoRA 层。在 Transformer 模型中,LoRA 层为查询和值投影矩阵创建并注入。在 keras.layers.MultiHeadAttention 中,查询/值投影层是 keras.layers.EinsumDense 层。
import math
class LoraLayer(keras.layers.Layer):
def __init__(
self,
original_layer,
rank=8,
alpha=32,
trainable=False,
**kwargs,
):
# We want to keep the name of this layer the same as the original
# dense layer.
original_layer_config = original_layer.get_config()
name = original_layer_config["name"]
kwargs.pop("name", None)
super().__init__(name=name, trainable=trainable, **kwargs)
self.rank = rank
self.alpha = alpha
self._scale = alpha / rank
self._num_heads = original_layer_config["output_shape"][-2]
self._hidden_dim = self._num_heads * original_layer_config["output_shape"][-1]
# Layers.
# Original dense layer.
self.original_layer = original_layer
# No matter whether we are training the model or are in inference mode,
# this layer should be frozen.
self.original_layer.trainable = False
# LoRA dense layers.
self.A = keras.layers.Dense(
units=rank,
use_bias=False,
# Note: the original paper mentions that normal distribution was
# used for initialization. However, the official LoRA implementation
# uses "Kaiming/He Initialization".
kernel_initializer=keras.initializers.VarianceScaling(
scale=math.sqrt(5), mode="fan_in", distribution="uniform"
),
trainable=trainable,
name=f"lora_A",
)
# B has the same `equation` and `output_shape` as the original layer.
# `equation = abc,cde->abde`, where `a`: batch size, `b`: sequence
# length, `c`: `hidden_dim`, `d`: `num_heads`,
# `e`: `hidden_dim//num_heads`. The only difference is that in layer `B`,
# `c` represents `rank`.
self.B = keras.layers.EinsumDense(
equation=original_layer_config["equation"],
output_shape=original_layer_config["output_shape"],
kernel_initializer="zeros",
trainable=trainable,
name=f"lora_B",
)
def call(self, inputs):
original_output = self.original_layer(inputs)
if self.trainable:
# If we are fine-tuning the model, we will add LoRA layers' output
# to the original layer's output.
lora_output = self.B(self.A(inputs)) * self._scale
return original_output + lora_output
# If we are in inference mode, we "merge" the LoRA layers' weights into
# the original layer's weights - more on this in the text generation
# section!
return original_output
将 LoRA 层注入模型
我们现在将 hack 原始 GPT-2 模型并将其 LoRA 层注入其中。在执行此操作之前,我们先做几件事:
- 删除之前的模型;
- 使用
tf.config.experimental.reset_memory_stats重置“峰值”GPU 内存使用量; - 加载新的 GPT-2 模型。
del gpt2_lm
del optimizer
del loss
# This resets "peak" memory usage to "current" memory usage.
tf.config.experimental.reset_memory_stats("GPU:0")
# Load the original model.
preprocessor = keras_hub.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=128,
)
lora_model = keras_hub.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=preprocessor,
)
我们现在将用新的 LoRA 层覆盖原始的查询/值投影矩阵。
for layer_idx in range(lora_model.backbone.num_layers):
# Change query dense layer.
decoder_layer = lora_model.backbone.get_layer(f"transformer_layer_{layer_idx}")
self_attention_layer = decoder_layer._self_attention_layer
# Allow mutation to Keras layer state.
self_attention_layer._tracker.locked = False
# Change query dense layer.
self_attention_layer._query_dense = LoraLayer(
self_attention_layer._query_dense,
rank=RANK,
alpha=ALPHA,
trainable=True,
)
# Change value dense layer.
self_attention_layer._value_dense = LoraLayer(
self_attention_layer._value_dense,
rank=RANK,
alpha=ALPHA,
trainable=True,
)
现在让我们进行一次前向传播,以确保我们仍然有一个有效的计算链。
lora_model(preprocessor(["LoRA is very useful for quick LLM finetuning"])[0])
pass
冻结整个 LLM,只有 LoRA 层应该是可训练的。
for layer in lora_model._flatten_layers():
lst_of_sublayers = list(layer._flatten_layers())
if len(lst_of_sublayers) == 1: # "leaves of the model"
if layer.name in ["lora_A", "lora_B"]:
layer.trainable = True
else:
layer.trainable = False
打印模型的摘要,并查看非可训练参数和总参数的数量是否正确。
在上一节中,我们计算出 LoRA 层的参数数量为 6,144。模型中的总可训练参数应为 num_layers * (query, value) * 6,144 = 12 * 2 * 6,144 = 147,456。非可训练参数的数量应与原始 GPT-2 模型中的总参数数量相同,即 124,439,808。
lora_model.summary()
Preprocessor: "gpt2_causal_lm_preprocessor_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Tokenizer (type) ┃ Vocab # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ gpt2_tokenizer_1 (GPT2Tokenizer) │ 50,257 │ └────────────────────────────────────────────────────┴─────────────────────────────────────────────────────┘
Model: "gpt2_causal_lm_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ padding_mask (InputLayer) │ (None, None) │ 0 │ - │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ token_ids (InputLayer) │ (None, None) │ 0 │ - │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ gpt2_backbone_1 │ (None, None, 768) │ 124,587,264 │ padding_mask[0][0], │ │ (GPT2Backbone) │ │ │ token_ids[0][0] │ ├───────────────────────────────┼───────────────────────────┼─────────────┼────────────────────────────────┤ │ token_embedding │ (None, None, 50257) │ 38,597,376 │ gpt2_backbone_1[0][0] │ │ (ReversibleEmbedding) │ │ │ │ └───────────────────────────────┴───────────────────────────┴─────────────┴────────────────────────────────┘
Total params: 124,587,264 (475.26 MB)
Trainable params: 147,456 (576.00 KB)
Non-trainable params: 124,439,808 (474.70 MB)
微调 LoRA GPT-2
现在我们已经 hack 并验证了 LoRA GPT-2 模型,让我们来训练它!
gpu_memory_callback = GPUMemoryCallback(
target_batches=[5, 10, 25, 50, 100, 150, 200, 300, 400, 500],
print_stats=True,
)
optimizer, loss = get_optimizer_and_loss()
lora_model.compile(
optimizer=optimizer,
loss=loss,
weighted_metrics=["accuracy"],
)
lora_model.fit(
train_ds,
epochs=EPOCHS,
callbacks=[gpu_memory_callback],
)
lora_model_memory_usage = gpu_memory_callback.memory_usage
2/500 [37m━━━━━━━━━━━━━━━━━━━━ 41s 84ms/step - accuracy: 0.2828 - loss: 3.7188
W0000 00:00:1701128576.353742 38699 graph_launch.cc:671] Fallback to op-by-op mode because memset node breaks graph update
500/500 ━━━━━━━━━━━━━━━━━━━━ 80s 81ms/step - accuracy: 0.2930 - loss: 3.6158
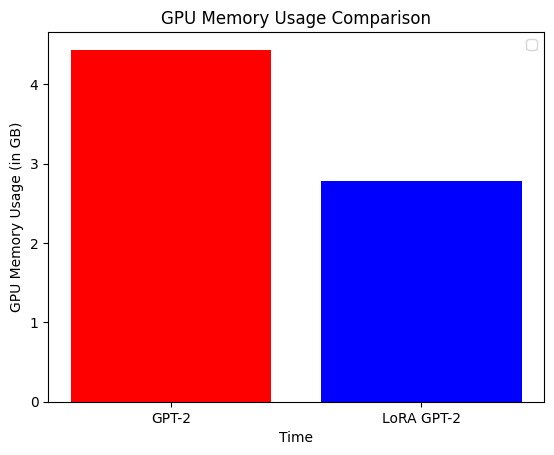
模型微调完成!在生成文本之前,让我们比较两个模型的训练时间和内存使用情况。GPT-2 在 16 GB Tesla T4 (Colab) 上的训练时间为 7 分钟,LoRA 为 5 分钟,减少了 30%。LoRA GPT-2 的内存使用量比 GPT-2 大约少 35%。
plt.bar(
["GPT-2", "LoRA GPT-2"],
[max(gpt2_lm_memory_usage), max(lora_model_memory_usage)],
color=["red", "blue"],
)
plt.xlabel("Time")
plt.ylabel("GPU Memory Usage (in GB)")
plt.title("GPU Memory Usage Comparison")
plt.legend()
plt.show()
WARNING:matplotlib.legend:No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
合并权重并生成文本!
LoRA 相对于其他适配器方法最大的优势之一是它不会产生任何额外的推理延迟。让我们来理解一下为什么。
回顾我们的 LoRA 方程:output = W0x + b0 + BAx。我们可以将其重写为:output = = Wx + b0 = (W0 + BA)x + b0,其中 W = W0 + BA。这意味着如果我们合并原始模型和适配器的权重,我们将执行与原始模型相同的计算!
for layer_idx in range(lora_model.backbone.num_layers):
self_attention_layer = lora_model.backbone.get_layer(
f"transformer_layer_{layer_idx}"
)._self_attention_layer
# Merge query dense layer.
query_lora_layer = self_attention_layer._query_dense
A_weights = query_lora_layer.A.kernel # (768, 1) (a, b)
B_weights = query_lora_layer.B.kernel # (1, 12, 64) (b, c, d)
increment_weights = tf.einsum("ab,bcd->acd", A_weights, B_weights) * (ALPHA / RANK)
query_lora_layer.original_layer.kernel.assign_add(increment_weights)
# Merge value dense layer.
value_lora_layer = self_attention_layer._value_dense
A_weights = value_lora_layer.A.kernel # (768, 1) (a, b)
B_weights = value_lora_layer.B.kernel # (1, 12, 64) (b, c, d)
increment_weights = tf.einsum("ab,bcd->acd", A_weights, B_weights) * (ALPHA / RANK)
value_lora_layer.original_layer.kernel.assign_add(increment_weights)
# Put back in place the original layers with updated weights
self_attention_layer._query_dense = query_lora_layer.original_layer
self_attention_layer._value_dense = value_lora_layer.original_layer
现在我们已准备好使用我们的 LoRA 模型生成文本了 : ).
# Freezing weights not necessary during generation since no weights are updated.
generate_text(lora_model, "I like basketball", max_length=MAX_GENERATION_LENGTH)
generate_text(
lora_model, "That Italian restaurant is", max_length=MAX_GENERATION_LENGTH
)
Output:
I like basketball. i've played this game for about a week and i'm pretty tired. today, i'm playing with my friend, who is a really good player. i'm a little older than the average player and i'm a bit too young.
Total Time Elapsed: 6.81s
Output:
That Italian restaurant is in the city center and is located on a street that was recently renovated for the summer.
i was in a group of friends and had a great time.
Total Time Elapsed: 0.32s
我们都完成了!